


IV. Dessiner un triangle▲
IV-A. Mise en place▲
IV-A-1. Code de base▲
IV-A-1-a. Structure générale▲
Dans le chapitre précédent, nous avons créé un projet Vulkan fonctionnel et nous l’avons testé à l’aide d’un code simple. Nous repartons de zéro, à partir du code suivant :
#include <vulkan/vulkan.h>
#include <iostream>
#include <stdexcept>
#include <cstdlib>
class HelloTriangleApplication {
public:
void run() {
initVulkan();
mainLoop();
cleanup();
}
private:
void initVulkan() {
}
void mainLoop() {
}
void cleanup() {
}
};
int main() {
HelloTriangleApplication app;
try {
app.run();
} catch (const std::exception& e) {
std::cerr << e.what() << std::endl;
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}Nous incluons d'abord le fichier d’en-tête Vulkan du SDK de LunarG, qui fournit les fonctions, les structures et les énumérations propres à la bibliothèque. Les fichiers d’en-tête <stdexcept> et <iostream> nous permettront de reporter et de traiter les erreurs. Le fichier d’en-tête <cstdlib> nous fournit les macros EXIT_FAILURE et EXIT_SUCCESS.
Le programme est écrit à l'intérieur d'une classe, dans laquelle seront stockés, comme membres privés, les objets Vulkan. La classe contiendra ainsi une fonction pour les initialiser, que nous appellerons initVulkan. Une fois l'initialisation réalisée, nous entrons dans la boucle principale, qui attend que nous fermions la fenêtre pour quitter le programme. Une fois la fenêtre fermée et que le programme quitte la fonction mainLoop(), nous nous assurons de libérer les ressources que nous avons utilisées avec la fonction cleanup().
Si nous rencontrons une quelconque erreur lors de l'exécution nous lèverons l’exception std::runtime_error avec un message descriptif, qui sera affiché sur le terminal depuis la fonction main(). Afin de nous assurer que nous récupérons bien toutes les erreurs, nous utilisons std::exception dans le catch. Nous verrons bientôt que la requête de certaines extensions peut mener à lever des exceptions.
À peu près tous les chapitres à partir de celui-ci présenteront une nouvelle fonction qui sera appelée dans initVulkan() ainsi qu’un ou plusieurs objets Vulkan, ajoutés comme membres privés de la classe et qui devront être détruits dans la fonction cleanup().
IV-A-1-b. Gestion des ressources▲
De la même façon qu'une quelconque ressource explicitement allouée par malloc doit être explicitement libérée par free, nous devrons explicitement détruire toutes les ressources Vulkan que nous allouerons. En C++, il est possible d’automatiser cela grâce au RAIIResource Acquisition Is Initialization ou aux pointeurs intelligents disponibles dans le fichier d’en-tête <memory>. Toutefois, dans ce tutoriel, nous resterons explicites pour toutes les opérations d’allocation et de libération des objets Vulkan. Après tout, un des objectifs de Vulkan est de rendre toute opération explicite afin d’éviter des erreurs. En laissant explicite la durée de vie des objets, il devient plus facile d’apprendre le fonctionnement de la bibliothèque.
Après avoir suivi ce tutoriel, vous pourrez parfaitement implémenter une gestion automatique des ressources en écrivant des classes C++ pour lesquelles le constructeur alloue l’objet Vulkan et le destructeur le libère. Aussi, vous pouvez fournir un opérateur de destruction personnalisé aux instances de std::unique_ptr et de std::shared_ptr. L'utilisation du RAII est à privilégier pour les projets Vulkan plus imposants, mais dans un objectif d’apprentissage, il est meilleur de savoir ce qui se passe en coulisse.
Les objets Vulkan peuvent être créés de deux manières. Soit ils sont directement créés avec une fonction du type vkCreateXXX, soit ils sont alloués à l'aide d'un autre objet avec une fonction vkAllocateXXX. Après vous être assuré que l’objet n'est plus utilisé, il faut le détruire en utilisant les fonctions vkDestroyXXX ou vkFreeXXX, respectivement. Les paramètres de ces fonctions varient suivant le type d’objet. Par contre, elles ont un paramètre commun : pAllocator. Ce paramètre optionnel vous permet de spécifier une fonction de callback permettant au programmeur de gérer lui-même l’allocation mémoire. Nous n'utiliserons jamais ce paramètre et indiquerons donc toujours nullptr.
IV-A-1-c. Intégrer GLFW▲
Vulkan fonctionne très bien sans fenêtre, notamment pour une utilisation de rendu hors écran (offscreen), mais c'est tout de même plus intéressant d'afficher quelque chose ! Remplacez d'abord la ligne #include <vulkan/vulkan.h> par :
#define GLFW_INCLUDE_VULKAN
#include <GLFW/glfw3.h>GLFW va alors inclure ses propres définitions et automatiquement charger le fichier d’en-tête de Vulkan. Ajoutez une fonction initWindow() et appelez-la depuis la fonction run() avant les autres fonctions. Nous utiliserons cette fonction pour initialiser GLFW et créer une fenêtre.
void run() {
initWindow();
initVulkan();
mainLoop();
cleanup();
}
private:
void initWindow() {
}Le premier appel dans initWindow() doit être glfwInit(), pour initialiser la bibliothèque. Dans la mesure où GLFW a été créée pour fonctionner avec OpenGL, nous devons lui demander de ne pas créer de contexte OpenGL avec l'appel suivant :
glfwWindowHint(GLFW_CLIENT_API, GLFW_NO_API);Le redimensionnement d’une fenêtre demande des précautions particulières, nous verrons cela plus tard et l'interdisons pour l'instant :
glfwWindowHint(GLFW_RESIZABLE, GLFW_FALSE);Il ne nous reste plus qu'à créer la fenêtre. Ajoutez un membre privé GLFWWindow* m_window pour en stocker une référence, et initialisez-la ainsi :
window = glfwCreateWindow(800, 600, "Vulkan", nullptr, nullptr);Les trois premiers paramètres indiquent respectivement la largeur, la hauteur et le titre de la fenêtre. Le quatrième vous permet optionnellement de spécifier un moniteur sur lequel ouvrir la fenêtre et le cinquième est spécifique à OpenGL.
Nous devrions plutôt utiliser des constantes pour la hauteur et la largeur dans la mesure où nous aurons besoin de ces valeurs dans le futur. J'ai donc ajouté au-dessus de la définition de la classe HelloTriangleApplication ces définitions :
const uint32_t WIDTH = 800;
const uint32_t HEIGHT = 600;et remplacez la création de la fenêtre par :
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);Vous avez maintenant une fonction initWindow() ressemblant à ceci :
void initWindow() {
glfwInit();
glfwWindowHint(GLFW_CLIENT_API, GLFW_NO_API);
glfwWindowHint(GLFW_RESIZABLE, GLFW_FALSE);
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);
}Pour nous assurer que l'application tourne jusqu'à ce qu'une erreur ou un clic sur la croix ne l'interrompe, nous devons écrire une petite boucle de gestion d'événements :
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
}
}Ce code est relativement simple. GLFW récupère tous les événements disponibles, puis vérifie qu'aucun d'entre eux ne correspond à une demande de fermeture de fenêtre. Ce sera aussi ici que nous appellerons la fonction qui affichera un triangle.
Une fois la fenêtre fermée, nous devons détruire toutes les ressources allouées et quitter GLFW. Voici la première version de la fonction cleanup :
void cleanup() {
glfwDestroyWindow(window);
glfwTerminate();
}Si vous lancez l'application, vous devriez voir une fenêtre nommée « Vulkan » qui se ferme en cliquant sur la croix. Maintenant que nous avons une base pour notre application Vulkan, créons notre premier objet VulkanInstance !
IV-A-2. Instance▲
IV-A-2-a. Création d'une instance Vulkan▲
La première chose à faire est d’initialiser Vulkan à travers une instance. Cette instance permet de faire le lien entre l'application et la bibliothèque. Pour la créer, il est nécessaire de fournir quelques informations au pilote concernant l’application.
Créez une fonction createInstance() et appelez-la depuis la fonction initVulkan() :
void initVulkan() {
createInstance();
}Ajoutez ensuite un membre à la classe pour conserver cette instance :
private:
VkInstance instance;Pour créer l'instance, nous devons d'abord remplir une structure avec des informations sur notre application. Techniquement, ces données sont optionnelles, mais elles peuvent fournir des informations utiles au pilote permettant d’optimiser des applications spécifiques (par exemple, lorsque l’application utilise un moteur très connu avec un comportement précis). Cette structure s'appelle VkApplicationInfo :
void createInstance() {
VkApplicationInfo appInfo{};
appInfo.sType = VK_STRUCTURE_TYPE_APPLICATION_INFO;
appInfo.pApplicationName = "Hello Triangle";
appInfo.applicationVersion = VK_MAKE_VERSION(1, 0, 0);
appInfo.pEngineName = "No Engine";
appInfo.engineVersion = VK_MAKE_VERSION(1, 0, 0);
appInfo.apiVersion = VK_API_VERSION_1_0;
}Comme mentionné précédemment, la plupart des structures Vulkan vous demandent d'expliciter leur propre type dans le champ sType. Aussi, cette structure fait partie de celles ayant un champ pNext pouvant pointer vers des informations supplémentaires. Ce champ est laissé à sa valeur par défaut : nullptr.
De nombreuses informations sont passées à Vulkan par le biais de structure et non pas de paramètre de fonctions. Nous devons remplir une autre structure pour compléter les informations nécessaires. Cette seconde structure est obligatoire et permet d’indiquer au pilote quelles sont les extensions globales et les couches de validation dont nous avons besoin. Le terme « global » indique qu’elles s’appliquent à l’intégralité du programme et non pas à un périphérique particulier. Ce concept sera plus clair dans les prochains chapitres.
VkInstanceCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO;
createInfo.pApplicationInfo = &appInfo;Les deux premiers paramètres sont simples. Les deux suivants spécifient les extensions globales dont nous avons besoin. Comme nous l'avons vu dans l'introduction, Vulkan n’a aucune connaissance de la plateforme sur laquelle il travaille et nous aurons donc besoin d’une extension pour s’interfacer avec le gestionnaire de fenêtres. GLFW possède une fonction très pratique qui nous donne la liste des extensions dont nous avons besoin pour cela :
uint32_t glfwExtensionCount = 0;
const char** glfwExtensions;
glfwExtensions = glfwGetRequiredInstanceExtensions(&glfwExtensionCount);
createInfo.enabledExtensionCount = glfwExtensionCount;
createInfo.ppEnabledExtensionNames = glfwExtensions;Les deux derniers membres de la structure indiquent les couches de validation à activer. Nous verrons cela dans le prochain chapitre, laissez ces champs vides pour le moment :
createInfo.enabledLayerCount = 0;Nous avons maintenant indiqué tout ce dont Vulkan a besoin pour créer une instance. Nous pouvons enfin appeler vkCreateInstance() :
VkResult result = vkCreateInstance(&createInfo, nullptr, &instance);Comme vous allez le constater, les fonctions de création d’un objet suivent un motif récurrent :
- un pointeur sur une structure contenant les informations de création de l’objet ;
- un pointeur sur une fonction d'allocation que nous laisserons toujours à nullptr ;
- un pointeur sur une variable pour stocker le nouvel objet.
Si tout s'est bien passé, l'instance devrait être stockée dans le membre VkInstance de la classe. Quasiment toutes les fonctions Vulkan retournent une valeur du type VkResult, pouvant être soit VK_SUCCESS soit un code d'erreur. Nul besoin de stocker le résultat, nous pouvons directement vérifier la valeur retournée ainsi :
if (vkCreateInstance(&createInfo, nullptr, &instance) != VK_SUCCESS) {
throw std::runtime_error("failed to create instance!");
}Lancez votre programme pour voir si l'instance s'est créée correctement.
IV-A-2-b. Vérification du support des extensions▲
Si vous regardez la documentation de la fonction vkCreateInstance() vous pourrez voir que l'un des messages d'erreur possible est VK_ERROR_EXTENSION_NOT_PRESENT. Nous pourrions juste interrompre le programme et afficher une erreur si une extension dont nous avons besoin est absente. Ce serait logique pour la plupart des extensions telles que celles pour le gestionnaire de fenêtres, mais quid du cas d’une extension optionnelle ?
La fonction vkEnumerateInstanceExtensionProperties() permet de récupérer la totalité des extensions supportées par le système avant la création de l'instance. Elle nécessite un pointeur vers une variable stockant le nombre d'extensions supportées et un tableau de VkExtensionProperties pour stocker les informations sur les extensions. Aussi, son premier paramètre est optionnel et permet de filtrer les extensions suivant une couche de validation spécifique. Nous l'ignorons pour le moment.
Pour allouer un tableau contenant les détails des extensions, nous devons déjà connaître le nombre de ces extensions. Vous pouvez récupérer celui-ci en définissant le dernier paramètre à nullptr :
uint32_t extensionCount = 0;
vkEnumerateInstanceExtensionProperties(nullptr, &extensionCount, nullptr);Maintenant, il suffit d’allouer un tableau pour contenir les informations sur les extensions (il faut aussi ajouter #include <vector> pour avoir accès aux std::vector) :
std::vector<VkExtensionProperties> extensions(extensionCount);Nous pouvons désormais récupérer les informations sur les extensions :
vkEnumerateInstanceExtensionProperties(nullptr, &extensionCount, extensions.data());La structure VkExtensionProperties contient le nom et la version de l'extension. Nous pouvons les afficher à l'aide d'une simple boucle (\t représente une tabulation) :
std::cout << "available extensions:\n";
for (const auto& extension : extensions) {
std::cout << '\t' << extension.extensionName << '\n';
}Vous pouvez ajouter ce code dans la fonction createInstance() si vous voulez afficher les informations liées au support de Vulkan sur la machine.
Petit défi : programmez une fonction qui vérifie si les extensions retournées par la fonction glfwGetRequiredInstanceExtensions() sont disponibles sur la machine.
IV-A-2-c. Libération des ressources▲
L’objet de type VkInstance ne doit être détruit qu'à la fin du programme. L’instance peut être libérée dans la fonction cleanup() grâce à la fonction vkDestroyInstance() :
void cleanup() {
vkDestroyInstance(instance, nullptr);
glfwDestroyWindow(window);
glfwTerminate();
}Les paramètres de cette fonction sont évidents. Comme préciser précédemment, les fonctions d’allocation et de désallocation possèdent un paramètre optionnel pour spécifier une fonction callback de gestion de la mémoire. Pour ignorer cela, nous passons nullptr. Toutes les autres ressources Vulkan que nous allons créer dans les chapitres suivants devront être libérées avant la destruction de l’instance Vulkan.
Avant de continuer sur des notions plus complexes, il est pratique de mettre en place des mécanismes de débogage grâce aux couches de validationCouches de validation.
IV-A-3. Couches de validation▲
IV-A-3-a. Qu’est-ce que les couches de validation ?▲
La bibliothèque Vulkan est conçue pour limiter au maximum le travail du pilote graphique. Par conséquent, par défaut, il n'y a aucune gestion des erreurs. Une erreur aussi simple que se tromper dans la valeur d'une énumération ou passer un pointeur nul comme argument non optionnel résulte en un crash ou un comportement indéfini. Dans la mesure où Vulkan nous demande d'être complètement explicite sur ce que nous faisons, il est facile de faire des petites erreurs comme utiliser une nouvelle fonctionnalité du GPU et ne pas l’avoir demandée lors de la création du périphérique logique.
Cependant de telles vérifications peuvent être ajoutées à la bibliothèque. Vulkan possède un système élégant appelé couches de validation. Ce sont des composants optionnels s'insérant dans les appels des fonctions Vulkan pour y ajouter des opérations. Voici quelques exemples de ce que peut apporte une couche de validation :
- comparer les valeurs des paramètres à celles de la spécification pour détecter une mauvaise utilisation ;
- suivre la création et la destruction des objets pour repérer les fuites de mémoire ;
- vérifier la sécurité des threads en suivant l'origine des appels ;
- afficher tous les appels de fonctions et leurs paramètres sur la sortie standard ;
- tracer les appels Vulkan pour une analyse de performances ou pour les rejouer ultérieurement.
Voici une implémentation d’exemple d’une fonction fournie par une couche de validation à des fins de diagnostic :
VkResult vkCreateInstance(
const VkInstanceCreateInfo* pCreateInfo,
const VkAllocationCallbacks* pAllocator,
VkInstance* instance) {
if (pCreateInfo == nullptr || instance == nullptr) {
log("Pointeur nul passé à un paramètre obligatoire !");
return VK_ERROR_INITIALIZATION_FAILED;
}
return real_vkCreateInstance(pCreateInfo, pAllocator, instance);
}Les couches de validations peuvent être combinées à loisir pour fournir toutes les fonctionnalités de débogage nécessaires. Vous pouvez activer les couches de validation lors du développement et complètement les désactiver lors du déploiement. En bref, le meilleur des deux mondes !
Vulkan ne fournit aucune couche de validation. Par contre, le SDK de LunarG fournit un ensemble de couches couvrant les erreurs courantes. Elles sont complètement open source, vous pouvez donc voir quelles erreurs sont détectées et contribuer à leur développement. Les utiliser est la meilleure manière de s’assurer que l’application fonctionne sur tous les pilotes et qu’elle ne repose pas sur un comportement indéfini.
Les couches de validation ne sont utilisables que si elles sont installées sur la machine. Par exemple, les couches de validation de LunarG ne sont disponibles que sur les PC ayant le SDK Vulkan installé.
Il a existé deux formes de couches de validation : les couches spécifiques à l'instance et celles spécifiques au périphérique. L’objectif était que les couches spécifiques à l’instance ne vérifient que les appels liés aux objets globaux de Vulkan (par exemple les instances) et que les couches spécifiques au périphérique ne vérifient que les appels liés au GPU. Les couches spécifiques au périphérique sont maintenant dépréciées. Les autres portent désormais sur tous les appels à Vulkan. Cependant la spécification recommande encore que nous activions les couches de validation au niveau du périphérique pour des raisons de compatibilité : certaines implémentations peuvent reposer sur ce comportement. Nous nous contenterons de spécifier les mêmes couches pour le périphérique logique que pour l’instance comme nous le verrons plus tard.
IV-A-3-b. Utiliser les couches de validation▲
Nous allons maintenant activer les couches de validation fournies par le SDK Vulkan. Comme pour les extensions, les couches de validation doivent être activées à partir de leur nom. Toutes les couches de validation standards sont rassemblées dans une couche fournie par le SDK sous le nom de VK_LAYER_KHRONOS_validation.
Premièrement, nous ajoutons au programme, deux variables de configuration pour indiquer les couches à activer et si elles doivent être activées ou non. La valeur de cette dernière repose sur la façon dont est compilé le programme. La macro NDEBUG faisant partie du standard C++ indique que le programme n’est pas compilé pour le débogage (No Debug).
const uint32_t WIDTH = 800;
const uint32_t HEIGHT = 600;
const std::vector<const char*> validationLayers = {
"VK_LAYER_KHRONOS_validation"
};
#ifdef NDEBUG
constexpr bool enableValidationLayers = false;
#else
constexpr bool enableValidationLayers = true;
#endifAjoutons une nouvelle fonction checkValidationLayerSupport(), qui devra vérifier si toutes les couches que nous voulons utiliser sont disponibles. D’abord, la fonction liste les couches de validation disponibles à l'aide de la fonction vkEnumerateInstanceLayerProperties(). Elle s'utilise de la même façon que vkEnumerateInstanceExtensionProperties(), que nous avons vue dans le chapitre précédent.
bool checkValidationLayerSupport() {
uint32_t layerCount;
vkEnumerateInstanceLayerProperties(&layerCount, nullptr);
std::vector<VkLayerProperties> availableLayers(layerCount);
vkEnumerateInstanceLayerProperties(&layerCount, availableLayers.data());
return false;
}Ensuite, nous vérifions si toutes les couches indiquées par validationLayers sont présentes dans la liste des couches disponibles sur la machine. Vous aurez besoin de <cstring> pour la fonction strcmp().
for (const char* layerName : validationLayers) {
bool layerFound = false;
for (const auto& layerProperties : availableLayers) {
if (strcmp(layerName, layerProperties.layerName) == 0) {
layerFound = true;
break;
}
}
if (!layerFound) {
return false;
}
}
return true;Nous pouvons maintenant utiliser cette fonction dans la fonction createInstance() :
void createInstance() {
if (enableValidationLayers && !checkValidationLayerSupport()) {
throw std::runtime_error("les couches de validation sont activées, mais ne sont pas disponibles !");
}
...
}Lancez maintenant le programme en mode debug et assurez-vous qu'il n’y a pas d’erreur. Si vous obtenez une erreur, référez-vous à la FAQRésolution des problèmes.
Finalement, modifions la structure VkCreateInstanceInfo() pour inclure les noms des couches de validations à utiliser, si elles doivent être activées :
if (enableValidationLayers) {
createInfo.enabledLayerCount = static_cast<uint32_t>(validationLayers.size());
createInfo.ppEnabledLayerNames = validationLayers.data();
} else {
createInfo.enabledLayerCount = 0;
}Si la vérification précédente s’est bien passée, la fonction vkCreateInstance() ne devrait jamais retourner VK_ERROR_LAYER_NOT_PRESENT, mais exécutez tout de même le programme pour en être sûr.
IV-A-3-c. Gestion personnalisée des messages▲
Par défaut, les couches de validation affichent leur message dans la console, mais on peut aussi s'occuper de l'affichage nous-mêmes en fournissant une fonction de callback explicite dans notre programme. Ceci nous permet également de choisir quels types de messages afficher, car tous ne sont pas des erreurs (fatales). Si vous ne voulez pas vous occuper de ça maintenant, vous pouvez sauter à la dernière section de ce chapitre.
Pour configurer un callback permettant de s'occuper des messages et des détails associés, nous devons mettre en place un messager de débogage (debug messenger) avec un callback en utilisant l'extension VK_EXT_debug_utils.
Créons d'abord une fonction getRequiredExtensions(). Elle nous fournira une liste des extensions nécessaires selon que nous activons les couches de validation ou non :
std::vector<const char*> getRequiredExtensions() {
uint32_t glfwExtensionCount = 0;
const char** glfwExtensions;
glfwExtensions = glfwGetRequiredInstanceExtensions(&glfwExtensionCount);
std::vector<const char*> extensions(glfwExtensions, glfwExtensions + glfwExtensionCount);
if (enableValidationLayers) {
extensions.push_back(VK_EXT_DEBUG_UTILS_EXTENSION_NAME);
}
return extensions;
}Les extensions spécifiées par GLFW seront toujours nécessaires, mais celle pour le débogage n'est ajoutée que conditionnellement. Notez l'utilisation de la macro VK_EXT_DEBUG_UTILS_EXTENSION_NAME au lieu du nom de l'extension pour éviter les erreurs de frappe.
Nous pouvons maintenant utiliser cette fonction dans la fonction createInstance() :
auto extensions = getRequiredExtensions();
createInfo.enabledExtensionCount = static_cast<uint32_t>(extensions.size());
createInfo.ppEnabledExtensionNames = extensions.data();Exécutez le programme et assurez-vous que vous ne recevez pas l'erreur VK_ERROR_EXTENSION_NOT_PRESENT. Nous ne devrions pas avoir besoin de vérifier sa présence sachant qu’elle est liée à la présence des couches de validation.
Intéressons-nous maintenant à la fonction de callback. Ajoutez une nouvelle fonction statique nommée debugCallback() à votre classe ayant pour prototype PFN_vkDebugUtilsMessengerCallbackEXT. VKAPI_ATTR et VKAPI_CALL assurent que la signature est la bonne pour que Vulkan puisse l’appeler.
static VKAPI_ATTR VkBool32 VKAPI_CALL debugCallback(
VkDebugUtilsMessageSeverityFlagBitsEXT messageSeverity,
VkDebugUtilsMessageTypeFlagsEXT messageType,
const VkDebugUtilsMessengerCallbackDataEXT* pCallbackData,
void* pUserData) {
std::cerr << "couche de validation : " << pCallbackData->pMessage << std::endl;
return VK_FALSE;
}Le premier paramètre indique la sévérité du message. Cela peut être :
- VK_DEBUG_UTILS_MESSAGE_SEVERITY_VERBOSE_BIT_EXT : message de diagnostic ;
- VK_DEBUG_UTILS_MESSAGE_SEVERITY_INFO_BIT_EXT : message d'information, telle que la création d’une ressource ;
- VK_DEBUG_UTILS_MESSAGE_SEVERITY_WARNING_BIT_EXT : message relevant un comportement qui n'est pas un bogue, mais qui pourrait en être un ;
- VK_DEBUG_UTILS_MESSAGE_SEVERITY_ERROR_BIT_EXT : message relevant un comportement invalide pouvant mener à un crash.
Les valeurs de cette énumération sont pensées de telle sorte qu’il est possible d’utiliser une comparaison pour savoir si un message est égal ou plus critique qu’un niveau de sévérité donné :
if (messageSeverity >= VK_DEBUG_UTILS_MESSAGE_SEVERITY_WARNING_BIT_EXT) {
// Le message est suffisamment important pour être affiché
}Le paramètre messageType peut prendre les valeurs suivantes :
- VK_DEBUG_UTILS_MESSAGE_TYPE_GENERAL_BIT_EXT : un événement sans rapport avec les performances ou la spécification ;
- VK_DEBUG_UTILS_MESSAGE_TYPE_VALIDATION_BIT_EXT : un événement provoquant une violation de la spécification et qui indique une erreur probable ;
- VK_DEBUG_UTILS_MESSAGE_TYPE_PERFORMANCE_BIT_EXT : une utilisation non optimale de Vulkan.
Le paramètre pCallbackData est une structure du type VkDebugUtilsMessengerCallbackDataEXT contenant les détails du message. Ses membres les plus importants sont :
- pMessage : le message sous la forme d'une chaîne de caractères terminée avec le caractère nul ;
- pObjects : un tableau d’objets Vulkan en rapport avec le message ;
- objectCount : le nombre d'objets dans le tableau.
Finalement, le paramètre pUserData est un pointeur sur une donnée quelconque que vous pouvez spécifier à la création du callback.
Le callback que nous programmons retourne un booléen déterminant si la fonction à l'origine de son appel doit être interrompue. Si elle retourne VK_TRUE, l'exécution de la fonction est interrompue et cette dernière retourne VK_ERROR_VALIDATION_FAILED_EXT. Cette fonctionnalité n'est normalement utilisée que pour tester les couches de validation elles-mêmes. Par conséquent, nous retournerons toujours VK_FALSE.
Il ne nous reste plus qu'à fournir notre fonction à Vulkan. Surprenamment, même le mécanisme de débogage se gère à travers une référence de type VkDebugUtilsMessengerEXT, que nous devrons explicitement créer et détruire. Le callback fait partie d’un messager de débogage et vous pouvez en posséder autant que vous le désirez. Ajoutez un membre à la classe pour le messager en dessous de l'instance :
VkDebugUtilsMessengerEXT callback;Ajoutez ensuite une fonction setupDebugMessenger() et appelez-la dans initVulkan() après createInstance() :
void initVulkan() {
createInstance();
setupDebugMessenger();
}
void setupDebugMessenger() {
if (!enableValidationLayers) return;
}Nous devons maintenant remplir une structure avec des informations sur le messager et sa fonction de callback :
VkDebugUtilsMessengerCreateInfoEXT createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_DEBUG_UTILS_MESSENGER_CREATE_INFO_EXT;
createInfo.messageSeverity = VK_DEBUG_UTILS_MESSAGE_SEVERITY_VERBOSE_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_SEVERITY_WARNING_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_SEVERITY_ERROR_BIT_EXT;
createInfo.messageType = VK_DEBUG_UTILS_MESSAGE_TYPE_GENERAL_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_TYPE_VALIDATION_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_TYPE_PERFORMANCE_BIT_EXT;
createInfo.pfnUserCallback = debugCallback;
createInfo.pUserData = nullptr; // OptionnelLe champ messageSeverity vous permet de filtrer pour quelle criticité de message votre fonction sera appelée. J'ai laissé tous les types sauf VK_DEBUG_UTILS_MESSAGE_SEVERITY_INFO_BIT_EXT, ce qui permet de recevoir toutes les informations à propos de possibles bogues tout en éliminant les informations génériques de débogage.
De manière similaire, le champ messageType vous permet de filtrer les types de messages pour lesquels la fonction de rappel sera appelée. J'y ai mis tous les types possibles. Vous pouvez très bien en désactiver s'ils ne vous servent à rien.
Finalement, le champ pfnUserCallback indique le pointeur vers la fonction de rappel. Optionnellement, vous pouvez passer un pointeur au champ pUserData, qui sera par la suite passé à la fonction de rappel au travers du paramètre pUserData. Par exemple, vous pouvez utiliser ce mécanisme pour passer un pointeur sur la classe HelloTriangleApplication.
Notez qu'il existe de nombreuses autres manières de configurer les messages des couches de validation et des fonctions de débogage. La configuration proposée ici offre une bonne base pour ce tutoriel. Référez-vous à la spécification de l'extension pour plus d'informations sur ces possibilités.
Cette structure doit maintenant être passée à la fonction vkCreateDebugUtilsMessengerEXT afin de créer l'objet VkDebugUtilsMessengerEXT. Malheureusement cette fonction fait partie d'une extension qui n’est pas chargée automatiquement. Nous devons donc trouver son adresse nous-mêmes grâce à la fonction vkGetInstancePorcAddr(). Nous allons créer notre propre fonction gérant ce genre de cas en fond. Je l'ai ajoutée au-dessus de la définition de la classe HelloTriangleApplication.
VkResult CreateDebugUtilsMessengerEXT(VkInstance instance, const VkDebugUtilsMessengerCreateInfoEXT* pCreateInfo, const VkAllocationCallbacks* pAllocator, VkDebugUtilsMessengerEXT* pCallback) {
auto func = (PFN_vkCreateDebugUtilsMessengerEXT) vkGetInstanceProcAddr(instance, "vkCreateDebugUtilsMessengerEXT");
if (func != nullptr) {
return func(instance, pCreateInfo, pAllocator, pCallback);
} else {
return VK_ERROR_EXTENSION_NOT_PRESENT;
}
}La fonction vkGetInstanceProcAddr() retourne nullptr si la fonction n'a pas pu être chargée. Nous pouvons maintenant utiliser cette fonction pour créer l’objet provenant de l’extension s'il est disponible :
if (CreateDebugUtilsMessengerEXT(instance, &createInfo, nullptr, &callback) != VK_SUCCESS) {
throw std::runtime_error("le messager n'a pas pu être créé!");
}Le troisième paramètre est l'invariable allocateur optionnel que nous laissons nullptr. Les autres paramètres sont assez logiques. La fonction callback est spécifique à l'instance et aux couches de validation, nous devons donc passer l'instance en premier argument. Vous allez croiser ce mécanisme pour d’autres objets « enfants ».
L’objet VkDebugUtilsMessengerEXT doit être libéré grâce à la fonction vkDestroyDebugUtilsMessengerEXT. De même, la fonction vkCreateDebugUtilsMessengerEXT doit être chargée manuellement.
Créez une autre fonction proxy juste en dessous de CreateDebugUtilsMessengerEXT :
void DestroyDebugUtilsMessengerEXT(VkInstance instance, VkDebugUtilsMessengerEXT debugMessenger, const VkAllocationCallbacks* pAllocator) {
auto func = (PFN_vkDestroyDebugUtilsMessengerEXT) vkGetInstanceProcAddr(instance, "vkDestroyDebugUtilsMessengerEXT");
if (func != nullptr) {
func(instance, debugMessenger, pAllocator);
}
}Assurez-vous que cette fonction est statique ou hors de la classe. Ensuite, nous pouvons l’appeler dans la fonction cleanup().
void cleanup() {
if (enableValidationLayers) {
DestroyDebugUtilsMessengerEXT(instance, callback, nullptr);
}
vkDestroyInstance(instance, nullptr);
glfwDestroyWindow(window);
glfwTerminate();
}IV-A-3-d. Déboguer la création et la destruction de l'instance▲
Même si nous avons des fonctionnalités de débogage grâce aux couches de validation, nous ne couvrons pas tous les cas. L’appel à la fonction vkCreateDebugUtilsMessengerEXT, nécessite une instance valide alors que vkDestroyDebugUtilsMessengerEXT doit être appelée avant que l’instance ne soit détruite. Par conséquent, il est impossible de déboguer les problèmes liés aux fonctions vkCreateInstance() et vkDestroyInstance().
En regardant en détail la documentation, vous allez trouver une méthode pour créer un messager de débogage spécifique à ces deux appels. Cela nécessite de passer simplement un pointeur à la structure VkDebugUtilsMessengerCreateInfoEXT dans le champ pNext de VkInstanceCreateInfo. Premièrement, déplacez le remplissage des informations du message dans une fonction à part :
void populateDebugMessengerCreateInfo(VkDebugUtilsMessengerCreateInfoEXT& createInfo) {
createInfo = {};
createInfo.sType = VK_STRUCTURE_TYPE_DEBUG_UTILS_MESSENGER_CREATE_INFO_EXT;
createInfo.messageSeverity = VK_DEBUG_UTILS_MESSAGE_SEVERITY_VERBOSE_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_SEVERITY_WARNING_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_SEVERITY_ERROR_BIT_EXT;
createInfo.messageType = VK_DEBUG_UTILS_MESSAGE_TYPE_GENERAL_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_TYPE_VALIDATION_BIT_EXT | VK_DEBUG_UTILS_MESSAGE_TYPE_PERFORMANCE_BIT_EXT;
createInfo.pfnUserCallback = debugCallback;
}
...
void setupDebugMessenger() {
if (!enableValidationLayers) return;
VkDebugUtilsMessengerCreateInfoEXT createInfo;
populateDebugMessengerCreateInfo(createInfo);
if (CreateDebugUtilsMessengerEXT(instance, &createInfo, nullptr, &debugMessenger) != VK_SUCCESS) {
throw std::runtime_error("Impossible de mettre en place le message de débogage !");
}
}Maintenant, nous pouvons réutiliser cette fonction dans la fonction createInstance() :
void createInstance() {
...
VkInstanceCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO;
createInfo.pApplicationInfo = &appInfo;
...
VkDebugUtilsMessengerCreateInfoEXT debugCreateInfo;
if (enableValidationLayers) {
createInfo.enabledLayerCount = static_cast<uint32_t>(validationLayers.size());
createInfo.ppEnabledLayerNames = validationLayers.data();
populateDebugMessengerCreateInfo(debugCreateInfo);
createInfo.pNext = (VkDebugUtilsMessengerCreateInfoEXT*) &debugCreateInfo;
} else {
createInfo.enabledLayerCount = 0;
createInfo.pNext = nullptr;
}
if (vkCreateInstance(&createInfo, nullptr, &instance) != VK_SUCCESS) {
throw std::runtime_error("Échec de création de l’instance !");
}
}La variable debugCreateInfo est en dehors du if pour qu'elle ne soit pas détruite avant l'appel à vkCreateInstance(). En créant le messager de débogage additionnel de cette façon, il sera appelé automatiquement durant les appels à vkCreateInstance() et vkDestroyInstance(). Il sera d’ailleurs détruit après ça.
IV-A-3-e. Test▲
Maintenant, plaçons intentionnellement une erreur pour voir les couches de validation en action. Temporairement, nous allons enlever l’appel à DestroyDebugUtilsMessengerEXT de la fonction cleanup() et exécuter notre programme. À la fermeture de celui-ci, vous devriez obtenir quelque chose de similaire :
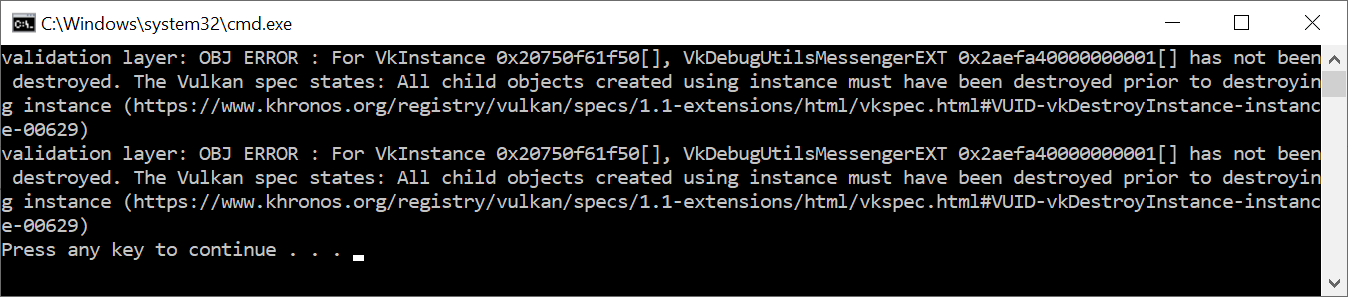
Si vous n’obtenez aucun message, vérifiez votre installation.
Si vous souhaitez voir quel appel a déclenché le message, vous pouvez ajouter un point d’arrêt dans la fonction de rappel et lire la liste d’appels.
IV-A-3-f. Configuration▲
Il y existe d’autres paramètres pour modifier le comportement des couches de validation que ceux que nous avons spécifiés dans la structure VkDebugUtilsMessengerCreateInfoEXT. Naviguez dans les dossiers du SDK Vulkan et allez dans le dossier Config. Vous trouverez un fichier vk_layer_settings.txt qui explique comment configurer les couches.
Pour configurer les couches pour votre propre application, copiez le fichier dans les dossiers Debug et Release de votre projet et suivez les instructions pour définir le comportement voulu. Toutefois, dans la suite du tutoriel, je partirai du principe que vous les avez laissées avec leur comportement par défaut.
Tout au long du tutoriel je laisserai quelques petites erreurs intentionnelles pour vous montrer à quel point les couches de validation sont pratiques et à quel point il est important de comprendre tout ce que vous faites avec Vulkan. Il est maintenant temps de s'intéresser aux périphériques Vulkan présent dans le systèmePériphériques physiques et famille de queues.
IV-A-4. Périphériques physiques et famille de queues▲
IV-A-4-a. Sélection d'un périphérique physique▲
Après l’initialisation de Vulkan grâce à l’instance de type VkInstance, nous devons chercher et sélectionner une carte graphique présente sur le système qui supporte les fonctionnalités dont nous avons besoin. En fait, nous pouvons en sélectionner autant que nous voulons et les utiliser simultanément, mais nous n’utiliserons que la première carte convenant à notre besoin.
Nous devons ajouter une fonction pickPhysicalDevice et l’appeler dans la fonction initVulkan() :
void initVulkan() {
createInstance();
setupDebugMessenger();
pickPhysicalDevice();
}
void pickPhysicalDevice() {
}Nous stockerons la carte graphique sélectionnée dans une variable de type VkPhysicalDevice membre de la classe. Cet objet sera détruit implicitement lorsque la variable du type VkInstance sera détruite. Il n’y a donc pas à s’en soucier dans fonction cleanup.
VkPhysicalDevice physicalDevice = VK_NULL_HANDLE;Obtenir la liste des cartes graphiques est similaire à l’obtention d’une liste des extensions. Cela débute par la récupération du nombre de périphériques présents :
uint32_t deviceCount = 0;
vkEnumeratePhysicalDevices(instance, &deviceCount, nullptr);S’il n’y a aucun périphérique supportant Vulkan, il ne sert à rien de continuer :
if (deviceCount == 0) {
throw std::runtime_error("Aucune carte graphique ne supporte Vulkan !");
}Dans le cas contraire, nous pouvons allouer un tableau pour contenir les références aux VkPhysicalDevice :
std::vector<VkPhysicalDevice> devices(deviceCount);
vkEnumeratePhysicalDevices(instance, &deviceCount, devices.data());Nous devons maintenant déterminer quel GPU correspond aux opérations que nous souhaitons effectuer. En effet, tous n’ont pas les mêmes capacités. Pour cela, nous créons une nouvelle fonction :
bool isDeviceSuitable(VkPhysicalDevice device) {
return true;
}Et nous allons vérifier si l’un des périphériques physiques correspond au besoin que nous spécifierons dans cette fonction.
for (const auto& device : devices) {
if (isDeviceSuitable(device)) {
physicalDevice = device;
break;
}
}
if (physicalDevice == VK_NULL_HANDLE) {
throw std::runtime_error("Impossible de trouver un GPU adéquat !");
}La section suivante introduira les premières contraintes à vérifier dans la fonction isDeviceSuitable(). Comme nous allons utiliser de plus en plus de fonctionnalités de Vulkan dans les prochains chapitres, nous allons ajouter de plus en plus de vérifications dans cette fonction.
IV-A-4-b. Vérification des fonctionnalités de base▲
Pour évaluer la compatibilité d'un périphérique, nous pouvons commencer par obtenir des informations dessus. Les propriétés telles que le nom, le type et la version supportée de Vulkan peuvent être obtenues grâce à la fonction vkGetPhysicalDeviceProperties().
VkPhysicalDeviceProperties deviceProperties;
vkGetPhysicalDeviceProperties(device, &deviceProperties);Le support des fonctionnalités optionnelles telles que la compression des textures, le support des nombres flottants sur 64 bits, le rendu sur plusieurs zones d’affichage (pour la réalité virtuelle) peuvent être obtenues grâce à la fonction vkGetPhysicalDeviceFeatures :
VkPhysicalDeviceFeatures deviceFeatures;
vkGetPhysicalDeviceFeatures(device, &deviceFeatures);Il est possible d’obtenir de nombreux autres détails sur les périphériques tels que la mémoire disponible ou les familles de queues.
Pour donner un exemple, nous allons considérer que notre application n’est utilisable que sur les cartes graphiques dédiées supportant les geometry shader. La fonction isDeviceSuitable ressemblera à cela :
bool isDeviceSuitable(VkPhysicalDevice device) {
VkPhysicalDeviceProperties deviceProperties;
VkPhysicalDeviceFeatures deviceFeatures;
vkGetPhysicalDeviceProperties(device, &deviceProperties);
vkGetPhysicalDeviceFeatures(device, &deviceFeatures);
return deviceProperties.deviceType == VK_PHYSICAL_DEVICE_TYPE_DISCRETE_GPU &&
deviceFeatures.geometryShader;
}Au lieu de ne choisir que le premier périphérique adéquat, nous pourrions attribuer un score à chacun d'entre eux et utiliser celui dont le score est le plus élevé. Vous pourriez ainsi favoriser une carte graphique dédiée en lui donnant un grand score, mais utiliser un GPU intégré au CPU si c’est le seul disponible. Cela pourrait être implémenté comme suit :
#include <map>
...
void pickPhysicalDevice() {
...
// Utilise une map ordonnée pour trier automatiquement sur le score
std::multimap<int, VkPhysicalDevice> candidates;
for (const auto& device : devices) {
int score = rateDeviceSuitability(device);
candidates.insert(std::make_pair(score, device));
}
// Vérifie si le meilleur candidat correspond au besoin
if (candidates.rbegin()->first > 0) {
physicalDevice = candidates.rbegin()->second;
} else {
throw std::runtime_error("Impossible de trouver un GPU adéquat !");
}
}
int rateDeviceSuitability(VkPhysicalDevice device) {
...
int score = 0;
// Les GPU dédiés ont un avantage significatif de par leur performance
if (deviceProperties.deviceType == VK_PHYSICAL_DEVICE_TYPE_DISCRETE_GPU) {
score += 1000;
}
// La taille maximale des textures impacte la qualité des graphismes
score += deviceProperties.limits.maxImageDimension2D;
// L’application ne peut fonctionner sans les geometry shaders
if (!deviceFeatures.geometryShader) {
return 0;
}
return score;
}Vous n'avez pas besoin d'implémenter tout ça pour ce tutoriel. C’est uniquement pour donner une idée sur la façon de concevoir le processus de sélection. Vous pourriez également vous contenter d'afficher les noms des cartes graphiques et laisser l'utilisateur choisir.
Comme nous ne faisons que commencer, nous prendrons la première carte supportant Vulkan :
bool isDeviceSuitable(VkPhysicalDevice device) {
return true;
}Dans la section suivante, nous discuterons de la première réelle fonctionnalité à vérifier.
IV-A-4-c. Familles de queues (queue families)▲
Il a été évoqué que la majorité des opérations avec Vulkan, de l'affichage jusqu'au chargement d'une texture sur le GPU, s'effectuent en envoyant des commandes à une queue. Il existe différents types de queues provenant de différentes familles de queues. De plus chaque famille de queues ne permet qu’un sous-ensemble de commandes. Par exemple, une famille de queues peut ne permettre que les commandes liées aux calculs et une autre ne permettre que les opérations liées aux transferts mémoire.
Nous devons vérifier les familles de queues supportées par le périphérique et lesquelles supportent les commandes que nous souhaitons utiliser. Pour cela, nous allons ajouter une nouvelle fonction findQueueFamilies() qui recherche toutes les queues dont nous ayons besoin.
Dès à présent, nous allons chercher une queue qui supporte les commandes graphiques. La fonction pourrait ressembler à ça :
uint32_t findQueueFamilies(VkPhysicalDevice device) {
// Logique pour trouver une famille de queues pour les opérations graphiques
}Toutefois, dans l’un des prochains chapitres nous devrons chercher une autre queue. Préparons-nous à ce cas et empaquetons l’indice dans une structure :
struct QueueFamilyIndices {
uint32_t graphicsFamily;
};
QueueFamilyIndices findQueueFamilies(VkPhysicalDevice device) {
QueueFamilyIndices indices;
// Logique pour trouver une famille de queues avec laquelle remplir la structure
return indices;
}Que se passe-t-il si une famille n'est pas disponible ? Nous pourrions lancer une exception dans la fonction findQueueFamilies(), mais cette fonction n'est pas vraiment le bon endroit pour prendre des décisions concernant le choix du bon périphérique. Par exemple, nous pourrions préférer des périphériques avec une queue de transfert dédiée, sans toutefois que ce soit une obligation. Par conséquent nous avons besoin d'indiquer si une certaine famille de queues a été trouvée.
Ce n'est pas très pratique d'utiliser une valeur magique pour indiquer la non-existence d'une famille alors que n'importe quelle valeur de uint32_t peut théoriquement être une valeur valide d'index de famille, 0 inclus. Heureusement, le C++17 introduit un type qui permet la distinction entre le cas où la valeur existe et celui où elle n'existe pas :
#include <optional>
...
std::optional<uint32_t> graphicsFamily;
std::cout << std::boolalpha << graphicsFamily.has_value() << std::endl; // false
graphicsFamily = 0;
std::cout << std::boolalpha << graphicsFamily.has_value() << std::endl; // truestd::optional est un wrapper qui ne contient aucune valeur tant que vous ne lui en assignez pas une. Vous pouvez, quel que soit le moment, lui demander s'il contient une valeur ou non en appelant la fonction has_value(). Nous pouvons donc changer le code comme suit :
#include <optional>
...
struct QueueFamilyIndices {
std::optional<uint32_t> graphicsFamily;
};
QueueFamilyIndices findQueueFamilies(VkPhysicalDevice device) {
QueueFamilyIndices indices;
// Assigne l’index à la famille de queues qui a été trouvée
return indices;
}Nous pouvons maintenant commencer à implémenter findQueueFamilies :
QueueFamilyIndices findQueueFamilies(VkPhysicalDevice device) {
QueueFamilyIndices indices;
...
return indices;
}La récupération de la liste des familles de queues disponibles se fait de la même manière que d'habitude, avec la fonction vkGetPhysicalDeviceQueueFamilyProperties() :
uint32_t queueFamilyCount = 0;
vkGetPhysicalDeviceQueueFamilyProperties(device, &queueFamilyCount, nullptr);
std::vector<VkQueueFamilyProperties> queueFamilies(queueFamilyCount);
vkGetPhysicalDeviceQueueFamilyProperties(device, &queueFamilyCount, queueFamilies.data());La structure VkQueueFamilyProperties contient les détails de la famille de queues, notamment le type des opérations supportées et le nombre de queues pouvant être créées pour cette famille . Nous devons trouver au moins une famille de queues supportant VK_QUEUE_GRAPHICS_BIT :
int i = 0;
for (const auto& queueFamily : queueFamilies) {
if (queueFamily.queueFlags & VK_QUEUE_GRAPHICS_BIT) {
indices.graphicsFamily = i;
}
i++;
}Nous avons maintenant une fonction pratique pour trouver une famille de queues et nous pouvons l’utiliser comme vérification dans la fonction isDeviceSuitable() pour s'assurer que le périphérique peut recevoir les commandes que nous voulons utiliser :
bool isDeviceSuitable(VkPhysicalDevice device) {
QueueFamilyIndices indices = findQueueFamilies(device);
return indices.graphicsFamily.has_value();
}Pour que ce soit plus pratique, nous allons aussi ajouter une fonction de vérification générique à la structure :
struct QueueFamilyIndices {
std::optional<uint32_t> graphicsFamily;
bool isComplete() {
return graphicsFamily.has_value();
}
};
...
bool isDeviceSuitable(VkPhysicalDevice device) {
QueueFamilyIndices indices = findQueueFamilies(device);
return indices.isComplete();
}Nous pouvons maintenant l’utiliser pour sortir plus tôt de la fonction findQueueFamilies :
for (const auto& queueFamily : queueFamilies) {
...
if (indices.isComplete()) {
break;
}
i++;
}Bien, c'est tout ce dont nous aurons besoin pour choisir le bon périphérique physique ! La prochaine étape est de créer un périphérique logiquePériphérique logique et queues pour s’y interfacer.
IV-A-5. Périphérique logique et queues▲
IV-A-5-a. Introduction▲
Après avoir sélectionné le périphérique physique, nous devons configurer un périphérique logique pour s’y interfacer. Le processus de création est similaire à celui de l'instance : nous devons décrire les fonctionnalités dont nous avons besoin. De plus, nous devons spécifier les queues à créer maintenant que nous savons quelles familles de queues sont disponibles. Vous pouvez même créer plusieurs périphériques logiques pour un même périphérique physique dans le cas où vous avez des contraintes changeantes.
Commencez par ajouter un nouveau membre à la classe pour stocker la référence au périphérique logique :
VkDevice device;Ensuite, ajoutez une fonction createLogicalDevice() qui sera appelée depuis initVulkan().
void initVulkan() {
createInstance();
setupDebugMessenger();
pickPhysicalDevice();
createLogicalDevice();
}
void createLogicalDevice() {
}IV-A-5-b. Spécifier les queues à créer▲
La création d'un périphérique logique nécessite de fournir plusieurs informations au travers de structures. La première de ces structures s'appelle VkDeviceQueueCreateInfo. Elle indique le nombre de queues que nous désirons pour chaque famille de queues. Pour le moment nous n'avons besoin que d'une queue de la famille des fonctionnalités graphiques.
QueueFamilyIndices indices = findQueueFamilies(physicalDevice);
VkDeviceQueueCreateInfo queueCreateInfo{};
queueCreateInfo.sType = VK_STRUCTURE_TYPE_DEVICE_QUEUE_CREATE_INFO;
queueCreateInfo.queueFamilyIndex = indices.graphicsFamily.value();
queueCreateInfo.queueCount = 1;Les pilotes actuels ne permettent de créer qu’un petit nombre de queues pour chaque famille et vous n’avez pas réellement besoin de plus d’une. En vérité, vous pouvez créer les tampons de commandes (command buffers) sur plusieurs threads puis les envoyer en une fois au thread principal avec un seul appel peu coûteux en performance.
Vulkan permet d'assigner des priorités aux queues pour influencer l’ordonnancement l’exécution des tampons de commandes par le biais d’un nombre à virgule flottante entre 0.0 et 1.0. Même avec une seule queue, vous devez définir la priorité :
float queuePriority = 1.0f;
queueCreateInfo.pQueuePriorities = &queuePriority;IV-A-5-c. Spécifier les fonctionnalités utilisées▲
Les prochaines informations à fournir sont les fonctionnalités du périphérique que nous allons utiliser. Ce sont celles dont nous avons vérifié la présence avec vkGetPhysicalDeviceFeatures() dans le chapitre précédent, tels que le support des geometry shaders. Pour le moment, nous n’avons besoin de rien de spécial. Nous pouvons donc nous contenter de créer la structure et de tout laisser à la valeur par défaut VK_FALSE. Nous reviendrons sur cette structure quand nous ferons des choses plus intéressantes avec Vulkan.
VkPhysicalDeviceFeatures deviceFeatures{};IV-A-5-d. Créer le périphérique logique▲
Avec ces deux structures prêtes, nous pouvons enfin remplir la structure principale appelée VkDeviceCreateInfo.
VkDeviceCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_DEVICE_CREATE_INFO;D’abord, ajoutez des pointeurs sur la création des queues et sur les fonctionnalités utilisées du périphérique :
createInfo.pQueueCreateInfos = &queueCreateInfo;
createInfo.queueCreateInfoCount = 1;
createInfo.pEnabledFeatures = &deviceFeatures;Le reste devrait vous rappeler la structure VkInstanceCreateInfo. Nous devons spécifier les extensions et les couches de validation. La différence est que ces dernières sont maintenant spécifiques au périphérique.
Par exemple, VK_KHR_swapchain est une extension spécifique au GPU. Celle-ci vous permet d’envoyer le rendu généré par ce périphérique aux fenêtres. Il est possible de rencontrer des périphériques Vulkan sans cette fonctionnalité, notamment si le matériel ne supporte que les opérations de calcul. Nous reviendrons sur cette extension dans le chapitre dédié à la swap chain.
Les anciennes implémentations de Vulkan faisaient la distinction entre les couches de validation spécifiques à l’instance et celles spécifiques au périphérique. Ce n’est maintenant plus le cas. Cela signifie que les champs enabledLayerCount et ppEnabledLayerNames de la structure VkDeviceCreateInfo sont ignorés dans les implémentations à jour. Toutefois, cela reste une bonne idée de les définir afin d’être compatible avec les anciennes implémentations.
createInfo.enabledExtensionCount = 0;
if (enableValidationLayers) {
createInfo.enabledLayerCount = static_cast<uint32_t>(validationLayers.size());
createInfo.ppEnabledLayerNames = validationLayers.data();
} else {
createInfo.enabledLayerCount = 0;
}Pour le moment, nous n’avons besoin d’aucune extension spécifique au périphérique.
C'est bon, nous pouvons maintenant instancier le périphérique logique en appelant la fonction vkCreateDevice().
if (vkCreateDevice(physicalDevice, &createInfo, nullptr, &device) != VK_SUCCESS) {
throw std::runtime_error("Échec de création du périphérique logique !");
}Le premier paramètre est le périphérique physique avec lequel s’interfacer. Ensuite vient la structure contenant les informations sur la queue et notre utilisation. Le troisième paramètre est un pointeur sur la fonction d’allocation personnalisée. Le dernier paramètre est un pointeur où stocker la référence au périphérique physique. Comme pour la fonction de création d’une instance, cette fonction retourne une erreur lors de l’activation d’une extension absente ou en indiquant l’utilisation de fonctionnalités non supportées.
Le périphérique doit être détruit dans la fonction cleanup() avec la fonction vkDestroyDevice() :
void cleanup() {
vkDestroyDevice(device, nullptr);
...
}Les périphériques logiques n'interagissent pas directement avec les instances. C’est pour cela que nous ne l’incluant pas comme paramètre.
IV-A-5-e. Récupérer des références aux queues▲
Les queues sont automatiquement créées avec le périphérique logique. Cependant nous n'avons aucune référence pour les utiliser. Ajoutez un membre à la classe pour stocker une référence à la queue :
VkQueue graphicsQueue;Les queues sont implicitement détruites lors de la destruction du périphérique logique. Nous n'avons donc pas à nous en charger dans la fonction cleanup().
Nous pouvons utiliser la fonction vkGetDeviceQueue() pour récupérer les références aux queues de chaque famille. Le premier paramètre est le périphérique logique, s’ensuit la famille de queues, l’index de queue et un pointeur sur la variable dans laquelle stocker la référence à la queue. Comme nous ne créons qu’une seule queue de cette famille, nous utilisons l’index 0.
vkGetDeviceQueue(device, indices.graphicsFamily.value(), 0, &graphicsQueue);Grâce au périphérique logique et les queues, nous pouvons maintenant utiliser la carte graphique ! Dans les prochains chapitres, nous allons configurer les ressources pour envoyer le rendu au gestionnaire de fenêtres.
IV-B. Envoi du rendu à l’écran▲
IV-B-1. Surface de fenêtre▲
Vulkan n’a aucune connaissance des spécificités de la plateforme et ne peut donc pas s’interfacer avec le gestionnaire de fenêtres. Pour créer une connexion permettant d’envoyer (présenter) les rendus à l'écran, nous devons utiliser les extensions Window System Integration (WSI). Nous verrons dans ce chapitre la première d’entre elles : VK_KHR_surface. Celle-ci nous offre un objet VkSurfaceKHR, un type abstrait représentant une surface sur laquelle afficher les rendus. Dans notre programme, cette surface est fournie par la fenêtre que nous avons ouverte grâce à GLFW.
L'extension VK_KHR_surface est une extension au niveau de l’instance et nous l’avons déjà activée. En effet, elle est incluse dans la liste retournée par la fonction glfwGetRequiredInstanceExtensions(). Par ailleurs, cette liste inclut aussi quelques autres extensions WSI que nous allons utiliser dans les prochains chapitres.
La surface liée à la fenêtre doit être créée juste après l'instance, car elle peut influencer le choix du périphérique physique. Nous ne nous intéressons à ce sujet que maintenant, car les surfaces font partie d’un sujet plus grand : celui des cibles de rendu et de la présentation du rendu. Ajouter ce sujet à la configuration de base aurait complexifié le tutoriel. Il est important de noter que les surfaces de fenêtre sont complètement optionnelles dans Vulkan et vous pouvez vous contenter d’un rendu hors écran. Vulkan vous offre ces possibilités sans vous demander de recourir à des astuces comme créer une fenêtre invisible (chose nécessaire en OpenGL).
IV-B-1-a. Création de la surface▲
Commencez par ajouter un membre surface à la classe, sous le messager de débogage.
VkSurfaceKHR surface;Bien que l'utilisation d'un objet VkSurfaceKHR soit indépendante de la plateforme, sa création ne l'est pas, car elle dépend du gestionnaire de fenêtres. Plus précisément, une telle fonction nécessite une référence à un HWND et à un HMODULE sous Windows. C'est pourquoi il existe des extensions spécifiques à la plateforme, dont VK_KHR_win32_surface sous Windows. Ces extensions sont automatiquement retournées par la fonction glfwGetRequiredInstanceExtensions().
Je vais présenter comment utiliser cette extension spécifique à la plateforme pour créer une surface sur Windows, mais nous n’allons pas l’utiliser dans ce tutoriel. En effet, ce n’est pas logique d’utiliser une bibliothèque comme GLFW pour ensuite utiliser du code spécifique à la plateforme. GLFW offre une fonction glfwCreateWindowSurface() qui gère les différences entre les plateformes pour nous. Toutefois, cela reste une bonne chose de voir comment cela fonctionne avant de s’en servir.
La surface liée à la fenêtre est un objet Vulkan et nécessite de remplir la structure VkWin32SurfaceCreateInfoKHR pour la créer. Elle possède deux paramètres importants : hwnd et hinstance. Ce sont les références à la fenêtre et au processus courant.
VkWin32SurfaceCreateInfoKHR createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_WIN32_SURFACE_CREATE_INFO_KHR;
createInfo.hwnd = glfwGetWin32Window(window);
createInfo.hinstance = GetModuleHandle(nullptr);Nous pouvons extraire le HWND de la fenêtre à l'aide de la fonction glfwGetWin32Window(). La fonction GetModuleHandle() retourne la référence HINSTANCE du thread courant.
La surface peut maintenant être créée avec vkCreateWin32SurfaceKHR(). Cette fonction prend en paramètre une instance, les détails pour la création de la surface, l'allocateur optionnel et la variable dans laquelle stocker la surface. Bien que cette fonction fasse partie d'une extension WSI, elle est chargée par le chargeur standard Vulkan, car celle-ci est couramment utilisée. Nous n'avons ainsi pas à la charger à la main :
if (vkCreateWin32SurfaceKHR(instance, &createInfo, nullptr, &surface) != VK_SUCCESS) {
throw std::runtime_error("Échec de création de la surface !");
}Ce processus est similaire pour toutes les plateformes. Par exemple, sous Linux, vous devez utiliser la fonction vkCreateXcbSurfaceKHR(). Les paramètres spécifiques à X11 sont une référence à la fenêtre et une connexion à XCB.
La fonction glfwCreateWindowSurface() implémente donc tout cela pour nous et utilise le code adéquat pour chaque plateforme. Nous devons maintenant l'intégrer à notre programme. Ajoutez la fonction createSurface() et appelez-la dans la fonction initVulkan() juste après la création de l’instance et l’appel à la fonction setupDebugMessenger() :
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
}
void createSurface() {
}L'appel à la fonction fournie par GLFW ne prend que quelques paramètres au lieu d'une structure, ce qui rend la fonction createSurface() simple :
void createSurface() {
if (glfwCreateWindowSurface(instance, window, nullptr, &surface) != VK_SUCCESS) {
throw std::runtime_error("Échec lors de la création de la surface !");
}
}Les paramètres sont l'instance Vulkan (de type VkInstance), le pointeur sur la fenêtre GLFW, l'allocateur optionnel et un pointeur sur une variable de type VkSurfaceKHR. GLFW ne fournit aucune fonction pour détruire une surface, mais nous pouvons le faire nous-mêmes grâce à une fonction Vulkan :
void cleanup() {
...
vkDestroySurfaceKHR(instance, surface, nullptr);
vkDestroyInstance(instance, nullptr);
...
}Détruisez bien la surface avant l'instance.
IV-B-1-b. Vérification du support d’envoi du rendu à la fenêtre▲
Bien que l'implémentation de Vulkan puisse supporter l’intégration du gestionnaire de fenêtre, cela ne signifie pas que tous les périphériques du système le supportent. Nous devons donc modifier la fonction isDeviceSuitable() pour nous assurer que le périphérique est capable d’envoyer (présenter) des images à la surface que nous avons créée. Cet envoi est une fonctionnalité spécifique à certaines familles de queue. La problématique est donc de trouver une famille qui supporte cette fonctionnalité.
En réalité, il est possible que les familles de queue supportant les commandes d'affichage ne supportent pas l’envoi du rendu et inversement. Par conséquent, nous devons gérer le cas où la queue pour l’envoi du rendu ne serait pas la même que celle des commandes graphiques et modifier la structure QueueFamilyIndices en conséquence :
struct QueueFamilyIndices {
std::optional<uint32_t> graphicsFamily;
std::optional<uint32_t> presentFamily;
bool isComplete() {
return graphicsFamily.has_value() && presentFamily.has_value();
}
};Nous devons ensuite modifier la fonction findQueueFamilies() pour qu'elle cherche une famille de queues pouvant supporter les commandes de présentation. La fonction permettant de vérifier cela est vkGetPhysicalDeviceSurfaceSupportKHR(). Elle accepte comme paramètres : le périphérique physique, l’indice de la famille de queues, la surface et elle stocke le résultat dans le quatrième paramètre qui est un booléen. Appelez-la depuis la même boucle que pour VK_QUEUE_GRAPHICS_BIT :
VkBool32 presentSupport = false;
vkGetPhysicalDeviceSurfaceSupportKHR(device, i, surface, &presentSupport);Il ne reste plus qu’à vérifier la valeur du booléen pour stocker la queue si elle correspond à notre besoin :
if (presentSupport) {
indices.presentFamily = i;
}Il est très probable que ces deux familles de queues soient en fait les mêmes, mais nous les traiterons comme si elles étaient différentes pour garder une approche uniforme. Vous pouvez cependant préférer un périphérique physique avec une famille de queues supportant le rendu et la présentation afin de légèrement améliorer les performances.
IV-B-1-c. Création de la queue de présentation▲
Il nous reste plus qu’à modifier la création du périphérique logique pour créer la queue de présentation et obtenir la référence de celle-ci (de type VkQueue). Ajoutez un membre à la classe pour cette référence :
VkQueue presentQueue;Nous avons besoin de plusieurs structures VkDeviceQueueCreateInfo, une pour chaque famille de queues. Une manière de gérer ces structures est d'utiliser un ensemble contenant tous les indices des familles nécessaires pour obtenir les queues voulues, comme ci-dessous :
#include <set>
...
QueueFamilyIndices indices = findQueueFamilies(physicalDevice);
std::vector<VkDeviceQueueCreateInfo> queueCreateInfos;
std::set<uint32_t> uniqueQueueFamilies = {indices.graphicsFamily.value(), indices.presentFamily.value()};
float queuePriority = 1.0f;
for (uint32_t queueFamily : uniqueQueueFamilies) {
VkDeviceQueueCreateInfo queueCreateInfo{};
queueCreateInfo.sType = VK_STRUCTURE_TYPE_DEVICE_QUEUE_CREATE_INFO;
queueCreateInfo.queueFamilyIndex = queueFamily;
queueCreateInfo.queueCount = 1;
queueCreateInfo.pQueuePriorities = &queuePriority;
queueCreateInfos.push_back(queueCreateInfo);
}Il faut ensuite modifier VkDeviceCreateInfo pour qu'il pointe sur le contenu du tableau :
createInfo.queueCreateInfoCount = static_cast<uint32_t>(queueCreateInfos.size());
createInfo.pQueueCreateInfos = queueCreateInfos.data();Si les familles de queues sont les mêmes, nous n'avons besoin de les indiquer qu'une seule fois. Il faut enfin ajouter un appel pour récupérer la référence sur la queue :
vkGetDeviceQueue(device, indices.presentFamily.value(), 0, &presentQueue);Si les queues sont les mêmes, les variables VkQueue auront la même valeur. Dans le prochain chapitre nous nous intéresserons aux swap chain et verrons comment elles permettent d’envoyer les rendus à l'écran.
IV-B-2. Swap chain▲
Vulkan ne possède pas de notion de tampon d’image par défaut. Il nous faut donc créer une infrastructure pour mettre en place ces tampons afin de les utiliser pour le rendu et de les afficher à l’écran. Sur Vulkan, une telle infrastructure s'appelle « swap chain » et doit être créée explicitement. Principalement, la « swap chain » est une liste d’images en attente d’être affichées. Notre application devra récupérer une des images de la file, dessiner dessus, puis la retourner à la file d'attente. Le fonctionnement de la file d'attente et les conditions d’envoi d’une image dépendent du paramétrage de la « swap chain ». Cependant, l'intérêt principal de la swap chain est de synchroniser l’envoi des images avec le rafraîchissement de l'écran.
IV-B-2-a. Vérification du support des swap chain▲
Toutes les cartes graphiques ne sont pas capables d’envoyer des images directement à l’écran, notamment dans les serveurs qui peuvent ne pas avoir de sortie vidéo. De plus, sachant que l’envoi d’image est très dépendant du gestionnaire de fenêtres et de la surface associée à la fenêtre, la « swap chain » ne fait pas partie du cœur de Vulkan. Vous devez vérifier le support de l’extension VK_KHR_swapchain et l’activer manuellement.
Pour cela, nous allons modifier la fonction isDeviceSuitable() pour vérifier si cette extension est supportée. Nous avons déjà vu comment lister les extensions supportées par un VkPhysicalDevice, donc cette modification devrait être assez simple. Notez que le fichier d’en-tête Vulkan fournit la macro VK_KHR_SWAPCHAIN_EXTENSION_NAME indiquant le nom de l’extension pour les « swap chain ». L’utiliser permet d’éviter les fautes de frappe.
Déclarez d'abord une liste d'extensions nécessaires au périphérique, comme nous l'avons fait pour la liste des couches de validation :
const std::vector<const char*> deviceExtensions = {
VK_KHR_SWAPCHAIN_EXTENSION_NAME
};Créez ensuite une nouvelle fonction nommée checkDeviceExtensionSupport() pour englober la nouvelle vérification et appelez-la depuis la fonction isDeviceSuitable() :
bool isDeviceSuitable(VkPhysicalDevice device) {
QueueFamilyIndices indices = findQueueFamilies(device);
bool extensionsSupported = checkDeviceExtensionSupport(device);
return indices.isComplete() && extensionsSupported;
}
bool checkDeviceExtensionSupport(VkPhysicalDevice device) {
return true;
}Modifiez le code de la fonction pour lister les extensions et vérifiez la présence de celles qui nous sont utiles :
bool checkDeviceExtensionSupport(VkPhysicalDevice device) {
uint32_t extensionCount;
vkEnumerateDeviceExtensionProperties(device, nullptr, &extensionCount, nullptr);
std::vector<VkExtensionProperties> availableExtensions(extensionCount);
vkEnumerateDeviceExtensionProperties(device, nullptr, &extensionCount, availableExtensions.data());
std::set<std::string> requiredExtensions(deviceExtensions.begin(), deviceExtensions.end());
for (const auto& extension : availableExtensions) {
requiredExtensions.erase(extension.extensionName);
}
return requiredExtensions.empty();
}J'ai décidé d'utiliser un std::set contenant des std::string pour représenter les extensions requises en attente de confirmation. De cette façon, nous pouvons ainsi facilement les éliminer en énumérant la liste des extensions disponibles. Vous pouvez également utiliser des boucles imbriquées comme dans la fonction checkValidationLayerSupport(). La différence en termes de performances n’est pas significative. Lancez le code et vérifiez que votre carte graphique est capable de gérer une « swap chain ». Normalement, la présence d’une queue de présentation implique la présence de l’extension de la « swap chain ». Toutefois, il est préférable de prendre ces précautions, de plus l’extension doit être activée explicitement.
IV-B-2-b. Activation des extensions du périphérique▲
L'utilisation de la « swap chain » nécessite l'activation de l’extension VK_KHR_swapchain. Son activation ne requiert qu'un léger changement à la structure de création du périphérique logique :
createInfo.enabledExtensionCount = static_cast<uint32_t>(deviceExtensions.size());
createInfo.ppEnabledExtensionNames = deviceExtensions.data();Supprimez bien l'ancienne ligne createInfo.enabledExtensionCount = 0;.
IV-B-2-c. Récupération des détails à propos du support de la « swap chain »▲
La seule vérification de la disponibilité d’une « swap chain » ne suffit pas. En effet, celle-ci pourrait être incompatible avec la surface liée à la fenêtre. La création d’une « swap chain » nécessite plus de paramètres que pour la création d’une instance ou du périphérique. Par conséquent, nous devons récupérer plus d’informations avant de pouvoir continuer.
Il y a trois types de propriétés que nous devrons vérifier :
- les possibilités basiques de la surface (nombre minimum et maximum d'images dans la « swap chain », hauteur et largeur minimale et maximale des images) ;
- les formats de la surface (format des pixels, palette de couleur) ;
- les modes d’envoi disponibles.
Nous utiliserons une structure comme celle de la fonction findQueueFamilies() pour stocker ces informations. Les trois catégories mentionnées plus haut se présentent sous la forme de la structure et des listes de structures suivantes :
struct SwapChainSupportDetails {
VkSurfaceCapabilitiesKHR capabilities;
std::vector<VkSurfaceFormatKHR> formats;
std::vector<VkPresentModeKHR> presentModes;
};Créons maintenant une nouvelle fonction querySwapChainSupport() qui remplira cette structure :
SwapChainSupportDetails querySwapChainSupport(VkPhysicalDevice device) {
SwapChainSupportDetails details;
return details;
}Cette section couvre la récupération des structures. Ce qu'elles signifient sera expliqué dans la section suivante.
Commençons par les capacités de base de la surface. Il suffit de demander ces informations et elles nous seront fournies sous la forme d'une structure du type VkSurfaceCapabilitiesKHR.
vkGetPhysicalDeviceSurfaceCapabilitiesKHR(device, surface, &details.capabilities);Cette fonction requiert que le périphérique physique (VkPhysicalDevice) et la surface de fenêtre (VkSurfaceKHR) soient passés en paramètres pour en obtenir les capacités. Toutes les fonctions récupérant des capacités de la « swap chain » demanderont ces paramètres, car ils en sont les composants centraux.
La prochaine étape est de récupérer les formats supportés par la surface. Comme c'est une liste de structures, cette acquisition suit le rituel en deux étapes :
uint32_t formatCount;
vkGetPhysicalDeviceSurfaceFormatsKHR(device, surface, &formatCount, nullptr);
if (formatCount != 0) {
details.formats.resize(formatCount);
vkGetPhysicalDeviceSurfaceFormatsKHR(device, surface, &formatCount, details.formats.data());
}Assurez-vous que le vecteur est redimensionné pour contenir tous les formats disponibles. Finalement, récupérez les modes de présentation supportés grâce à la fonction vkGetPhysicalDeviceSurfacePresentModesKHR() :
uint32_t presentModeCount;
vkGetPhysicalDeviceSurfacePresentModesKHR(device, surface, &presentModeCount, nullptr);
if (presentModeCount != 0) {
details.presentModes.resize(presentModeCount);
vkGetPhysicalDeviceSurfacePresentModesKHR(device, surface, &presentModeCount, details.presentModes.data());
}Toutes les informations sont dans des structures. Il faut donc améliorer une nouvelle fois la fonction isDeviceSuitable() pour vérifier si le support de la « swap chain » correspond à notre besoin. Pour ce tutoriel, une « swap chain » est adéquate si elle a un format d’image et un mode de présentation correspondant à la surface que nous avons.
bool swapChainAdequate = false;
if (extensionsSupported) {
SwapChainSupportDetails swapChainSupport = querySwapChainSupport(device);
swapChainAdequate = !swapChainSupport.formats.empty() && !swapChainSupport.presentModes.empty();
}Il est important de ne vérifier le support de la « swap chain » qu'après s'être assuré que l'extension est disponible. La dernière ligne de la fonction devient donc :
return indices.isComplete() && extensionsSupported && swapChainAdequate;IV-B-2-d. Choix des bons paramètres pour la « swap chain »▲
Si les conditions validées par la fonction swapChainAdequate() sont remplies, alors le support de la swap chain est assuré. Il existe cependant plusieurs modes ayant chacun leur avantage. Nous allons maintenant écrire quelques fonctions qui détermineront les bons paramètres pour obtenir la meilleure « swap chain » possible. Il y a trois types de paramètres à déterminer :
- le format de la surface (profondeur de la couleur) ;
- le mode de présentation (les conditions d’échange des images vers l’écran) ;
- la zone d’échange (swap extent) (la résolution des images dans la « swap chain »).
Pour chacun de ces paramètres, nous aurons une valeur idéale que nous choisirons si elle est disponible, sinon, nous nous rabattrons sur ce qui il y aura de mieux.
IV-B-2-d-i. Format de la surface▲
La fonction utilisée pour déterminer ce paramètre commence ainsi. Nous lui passerons comme argument le membre formats de la structure SwapChainSupportDetails.
VkSurfaceFormatKHR chooseSwapSurfaceFormat(const std::vector<VkSurfaceFormatKHR>& availableFormats) {
}Chaque VkSurfaceFormatKHR contient une propriété format et une propriété colorSpace. Le format indique les canaux de couleur disponibles et les types. Par exemple VK_FORMAT_B8G8R8A8_SRGB signifie que nous stockons les canaux de couleur R, G, B et A dans cet ordre, dans des entiers non signés sur 8 bits. La propriété colorSpace permet de vérifier que l’espace de couleur sRGB est supporté ou non par le biais de l’indicateur VK_COLOR_SPACE_SRGB_NONLINEAR_KHR.
L’indicateur VK_COLOR_SPACE_SRGB_NONLINEAR_KHR s’appelait VK_COLOSPACE_SRGB_NONLINEAR_KHR dans de précédentes versions de la spécification.
Nous utiliserons, si disponible, l’espace de couleur sRGB. Ce dernier donne des résultats mieux perçus par l’œil humain. Aussi, c’est quasiment l’espace de couleur standard pour les images, telles que les textures que nous allons utiliser plus tard. Par conséquent, nous devons aussi utiliser un format de couleurs SRGB. Le format VK_FORMAT_B8G8R8A8_SRGB est l’un des plus courants.
Itérons sur la liste et voyons si la meilleure combinaison est disponible :
for (const auto& availableFormat : availableFormats) {
if (availableFormat.format == VK_FORMAT_B8G8R8A8_SRGB && availableFormat.colorSpace == VK_COLOR_SPACE_SRGB_NONLINEAR_KHR) {
return availableFormat;
}
}Si cette approche échoue, nous pouvons trier les combinaisons disponibles suivant leur « qualité ». Mais, la plupart du temps, c’est suffisant de simplement utiliser le premier format disponible.
VkSurfaceFormatKHR chooseSwapSurfaceFormat(const std::vector<VkSurfaceFormatKHR>& availableFormats) {
for (const auto& availableFormat : availableFormats) {
if (availableFormat.format == VK_FORMAT_B8G8R8A8_SRGB && availableFormat.colorSpace == VK_COLOR_SPACE_SRGB_NONLINEAR_KHR) {
return availableFormat;
}
}
return availableFormats[0];
}IV-B-2-d-ii. Mode de présentation▲
Le mode de présentation est clairement le paramètre le plus important pour la « swap chain », car il indique les conditions pour afficher les images à l’écran. Il existe quatre modes avec Vulkan :
- VK_PRESENT_MODE_IMMEDIATE_KHR : les images émises par votre application sont directement envoyées à l'écran, ce qui peut produire des déchirures (tearing) ;
- VK_PRESENT_MODE_FIFO_KHR : la « swap chain » est une file d'attente. L'écran récupère l'image en haut de la pile quand il est rafraîchi, alors que le programme insère les images rendues à l'arrière. Si la queue est pleine, le programme doit attendre. Ce mode est très similaire à la synchronisation verticale utilisée par la plupart des jeux vidéo modernes. L'instant durant lequel l'écran est rafraîchi s'appelle l’intervalle de rafraîchissement vertical (vertical blank) ;
- VK_PRESENT_MODE_FIFO_RELAXED_KHR : ce mode ne diffère du précédent que lorsque l'application est en retard et que la queue est vide pendant l’intervalle de rafraîchissement vertical. Au lieu d'attendre le prochain rafraîchissement, une image arrivant dans la file d'attente sera immédiatement transmise à l'écran. Cela peut entraîner des déchirures.
- VK_PRESENT_MODE_MAILBOX_KHR : ce mode est une autre variation du second mode. Au lieu de bloquer l'application quand la file d'attente est pleine, les images présentes dans la queue sont remplacées par les nouvelles. Ce mode peut être utilisé pour implémenter le triple buffering, qui vous permet d'éliminer les déchirures sur les images tout en ayant moins de problèmes de latence qu’avec la synchronisation verticale standard reposant sur du double buffering.
Seul le mode VK_PRESENT_MODE_FIFO_KHR est toujours disponible. Nous aurons donc encore à écrire une fonction pour trouver le meilleur mode disponible :
VkPresentModeKHR chooseSwapPresentMode(const std::vector<VkPresentModeKHR>& availablePresentModes) {
return VK_PRESENT_MODE_FIFO_KHR;
}Je pense que le triple buffering est un très bon compromis. Il permet d’éviter les déchirures tout en gardant une latence très basse en affichant les images qui sont à jour. Vérifions si ce mode est disponible dans la liste :
VkPresentModeKHR chooseSwapPresentMode(const std::vector<VkPresentModeKHR>& availablePresentModes) {
for (const auto& availablePresentMode : availablePresentModes) {
if (availablePresentMode == VK_PRESENT_MODE_MAILBOX_KHR) {
return availablePresentMode;
}
}
return VK_PRESENT_MODE_FIFO_KHR;
}IV-B-2-d-iii. La zone d’échange▲
Il ne nous reste plus qu'une propriété majeure, pour laquelle nous allons créer une dernière fonction :
VkExtent2D chooseSwapExtent(const VkSurfaceCapabilitiesKHR& capabilities) {
}La zone d’échange (swap extent) correspond à la résolution des images dans la « swap chain ». Généralement, elle est égale à la résolution de la fenêtre que nous utilisons. L'étendue des résolutions disponibles est définie dans la structure VkSurfaceCapabilitiesKHR. Vulkan nous demande de faire correspondre la résolution de la fenêtre en indiquant la largeur et la hauteur dans la propriété currentExtent. Cependant, certains gestionnaires de fenêtres nous permettent de choisir une résolution différente, cela peut être précisé grâce à une valeur spéciale (la valeur maximale pour un uint32_t) pour la largeur et la hauteur. Dans ce cas, nous choisirons la résolution correspondant le mieux à la taille de la fenêtre, comprise entre minImageExtent et maxImageExtent.
#include <cstdint> // Nécessaire pour UINT32_MAX
...
VkExtent2D chooseSwapExtent(const VkSurfaceCapabilitiesKHR& capabilities) {
if (capabilities.currentExtent.width != UINT32_MAX) {
return capabilities.currentExtent;
} else {
VkExtent2D actualExtent = {WIDTH, HEIGHT};
actualExtent.width = std::max(capabilities.minImageExtent.width, std::min(capabilities.maxImageExtent.width, actualExtent.width));
actualExtent.height = std::max(capabilities.minImageExtent.height, std::min(capabilities.maxImageExtent.height, actualExtent.height));
return actualExtent;
}
}Les fonctions std::min et std::max sont utilisées pour limiter les valeurs WIDTH et HEIGHT entre le minimum et le maximum supportés par l'implémentation. Incluez le fichier d’en-tête <algorithm> pour les utiliser.
IV-B-2-e. Création de la swap chain▲
Maintenant que nous avons toutes ces fonctions nous aidant à faire un choix, nous pouvons enfin créer une « swap chain ».
Créez une fonction createSwapChain(). Elle commence par récupérer le résultat des fonctions précédentes. Appelez-la depuis initVulkan() après la création du périphérique logique.
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
}
void createSwapChain() {
SwapChainSupportDetails swapChainSupport = querySwapChainSupport(physicalDevice);
VkSurfaceFormatKHR surfaceFormat = chooseSwapSurfaceFormat(swapChainSupport.formats);
VkPresentModeKHR presentMode = chooseSwapPresentMode(swapChainSupport.presentModes);
VkExtent2D extent = chooseSwapExtent(swapChainSupport.capabilities);
}En plus de ces propriétés, nous devons décider du nombre d’images que nous souhaitons avoir dans la « swap chain ». L’implémentation informe du nombre minimal pour fonctionner :
uint32_t imageCount = swapChainSupport.capabilities.minImageCount;Toutefois, se contenter de la limite basse augmente le risque d’être dans l’attente du pilote lors de la récupération d’une nouvelle image pour effectuer le rendu. Il est donc recommandé de demander au moins une image de plus que le minimum :
uint32_t imageCount = swapChainSupport.capabilities.minImageCount + 1;Il nous faut également prendre en compte le maximum d'images supportées par l'implémentation. La valeur 0 signifie qu'il n'y a pas de maximum.
if (swapChainSupport.capabilities.maxImageCount > 0 && imageCount > swapChainSupport.capabilities.maxImageCount) {
imageCount = swapChainSupport.capabilities.maxImageCount;
}Comme la tradition le veut avec la création des objets dans Vulkan, la création d'une « swap chain » nécessite de remplir une grande structure. Elle commence de manière habituelle :
VkSwapchainCreateInfoKHR createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_SWAPCHAIN_CREATE_INFO_KHR;
createInfo.surface = surface;Après avoir indiqué la surface à laquelle la « swap chain » doit être liée, nous spécifions les détails sur les images de la « swap chain » :
createInfo.minImageCount = imageCount;
createInfo.imageFormat = surfaceFormat.format;
createInfo.imageColorSpace = surfaceFormat.colorSpace;
createInfo.imageExtent = extent;
createInfo.imageArrayLayers = 1;
createInfo.imageUsage = VK_IMAGE_USAGE_COLOR_ATTACHMENT_BIT;La propriété imageArrayLayers indique le nombre de couches de chaque image. Ce sera toujours 1 sauf si vous développez une application stéréoscopique 3D. Le champ de bits imageUsage spécifie le type d'opérations que nous effectuerons avec les images de la « swap chain ». Dans ce tutoriel, nous effectuerons un rendu directement sur les images, c’est-à-dire qu’elles seront utilisées comme attaches de couleur. Il est aussi possible d’effectuer le rendu dans une autre image en vue de faire des effets de post traitement. Dans ce cas, vous devrez utiliser une valeur comme VK_IMAGE_USAGE_TRANSFER_DST_BIT et utiliser une opération mémoire pour transférer l’image rendue vers l’image de la « swap chain ».
QueueFamilyIndices indices = findQueueFamilies(physicalDevice);
uint32_t queueFamilyIndices[] = {indices.graphicsFamily.value(), indices.presentFamily.value()};
if (indices.graphicsFamily != indices.presentFamily) {
createInfo.imageSharingMode = VK_SHARING_MODE_CONCURRENT;
createInfo.queueFamilyIndexCount = 2;
createInfo.pQueueFamilyIndices = queueFamilyIndices;
} else {
createInfo.imageSharingMode = VK_SHARING_MODE_EXCLUSIVE;
createInfo.queueFamilyIndexCount = 0; // Optionnel
createInfo.pQueueFamilyIndices = nullptr; // Optionnel
}Ensuite, nous devrons indiquer comment gérer les images de la « swap chain » utilisées par plusieurs familles de queues. Cela sera le cas dans notre application si la queue des graphismes n'est pas la même que la queue de présentation. Nous devrons alors dessiner avec la queue graphique puis fournir l'image à la queue de présentation. Il existe deux manières de gérer les images accédées par plusieurs queues :
- VK_SHARING_MODE_EXCLUSIVE : une image n'est accessible que par une queue à la fois et sa gestion doit être explicitement transférée à une autre queue pour pouvoir être utilisée dans une autre famille. Cette option offre de meilleures performances ;
- VK_SHARING_MODE_CONCURRENT : les images peuvent être simplement utilisées par différentes familles de queues.
Si nous avons deux familles de queues différentes, nous utiliserons le mode concurrent pour éviter d'ajouter un chapitre sur la possession des ressources, car cela nécessite des concepts que nous ne pourrons comprendre correctement que plus tard. Le mode concurrent vous demande de spécifier à l'avance les queues qui partageront les images en utilisant les paramètres queueFamilyIndexCount et pQueueFamilyIndices. Si les familles de queue pour les graphismes et la présentation sont les mêmes, ce qui est le cas sur la plupart des cartes graphiques, nous devons rester sur le mode exclusif, car le mode concurrent requiert au moins deux familles de queues différentes.
createInfo.preTransform = swapChainSupport.capabilities.currentTransform;Nous pouvons spécifier une transformation à appliquer aux images quand elles entrent dans la « swap chain » si cela est supporté (à vérifier avec la propriété supportedTransforms dans capabilities). Cela peut être une rotation de 90 degrés ou une symétrie verticale. Si vous ne voulez pas de transformation, spécifiez la transformation actuelle.
createInfo.compositeAlpha = VK_COMPOSITE_ALPHA_OPAQUE_BIT_KHR;Le champ compositeAlpha indique si le canal alpha doit être utilisé pour mélanger les couleurs avec celles des autres fenêtres dans le gestionnaire de fenêtres. Vous voudrez quasiment tout le temps ignorer cela et indiquer VK_COMPOSITE_ALPHA_OPAQUE_BIT_KHR :
createInfo.presentMode = presentMode;
createInfo.clipped = VK_TRUE;Le membre presentMode est assez simple. Si le membre clipped est à VK_TRUE, nous indiquons que les couleurs des pixels masqués, notamment par d'autres fenêtres, ne nous intéressent pas. Si vous n'avez pas un besoin particulier de lire ces informations et d’en obtenir des résultats stables, vous obtiendrez de meilleures performances en activant ce mode.
createInfo.oldSwapchain = VK_NULL_HANDLE;Il nous reste un dernier champ, oldSwapChain. Il est possible avec Vulkan que la « swap chain » devienne invalide ou peu performante pendant l’exécution de votre application. Notamment, cela arrive lorsque la fenêtre est redimensionnée. Dans ce cas, la « swap chain » doit être intégralement recréée et vous devez fournir une référence pointant vers l’ancienne « swap chain ». C'est un sujet compliqué que nous aborderons dans un futur chapitreRecréation de la « swap chain ». Pour le moment, nous gérons seulement la création de la « swap chain ».
Ajoutez un membre à la classe pour stocker l'objet VkSwapchainKHR :
VkSwapchainKHR swapChain;Il ne reste plus qu’à appeler la fonction vkCreateSwapchainKHR() pour créer la « swap chain » :
if (vkCreateSwapchainKHR(device, &createInfo, nullptr, &swapChain) != VK_SUCCESS) {
throw std::runtime_error("Échec de création de la swap chain !");
}La fonction accepte comme paramètre le périphérique logique, les informations de création de la « swap chain », l'allocateur optionnel et la variable pour stocker la « swap chain » créée. Cet objet devra être explicitement détruit à l'aide de la fonction vkDestroySwapchainKHR() avant de détruire le périphérique logique :
void cleanup() {
vkDestroySwapchainKHR(device, swapChain, nullptr);
...
}Lancez l'application et contemplez la création de la « swap chain » ! Si vous obtenez une erreur de violation d'accès dans la fonction vkCreateSwapchainKHR() ou que vous obtenez un message similaire à Failed to find 'vkGetInstanceProcAddress' in layer SteamOverlayVulkanLayer.ddl, allez voir la FAQ à propos de la surcouche SteamRésolution des problèmes.
Essayez de retirer la ligne createInfo.imageExtent = extent; tout en ayant les couches de validation actives. Vous verrez que l'une d'entre elles remontera l'erreur et un message vous sera envoyé :
![[ALT-PASTOUCHE]](./images/swap_chain_validation_layer.png)
IV-B-2-f. Récupération des images de la « swap chain »▲
La « swap chain » est enfin créée. Il nous faut maintenant obtenir les images (VkImage) contenues dedans. Nous les utiliserons lors du rendu que nous verrons dans les chapitres suivants. Ajoutez un membre à la classe pour les stocker :
std::vector<VkImage> swapChainImages;Ces images ont été créées par Vulkan lors de la création de la « swap chain » et elles seront automatiquement supprimées avec sa destruction. Nous n'aurons donc rien à rajouter dans la fonction cleanup().
J’ajoute le code de récupération des images à la fin de la fonction createSwapChain(), juste après l'appel à vkCreateSwapchainKHR(). L’obtention des références est très similaire à ce que nous avons déjà fait lorsque nous avons récupéré un tableau d’objets provenant de Vulkan. Souvenez-vous que nous avons seulement spécifié un nombre minimal d’images dans la « swap chain ». L’implémentation peut en avoir créé plus. C’est pourquoi nous commençons par récupérer le nombre d’images avec la fonction vkGetSwapchainImagesKHR() avant de redimensionner le conteneur pour enfin obtenir les références.
vkGetSwapchainImagesKHR(device, swapChain, &imageCount, nullptr);
swapChainImages.resize(imageCount);
vkGetSwapchainImagesKHR(device, swapChain, &imageCount, swapChainImages.data());Une dernière chose : conservez le format et la zone d’échange de la « swap chain ». Nous en aurons besoin dans de futurs chapitres.
VkSwapchainKHR swapChain;
std::vector<VkImage> swapChainImages;
VkFormat swapChainImageFormat;
VkExtent2D swapChainExtent;
...
swapChainImageFormat = surfaceFormat.format;
swapChainExtent = extent;Nous avons maintenant un ensemble d'images sur lesquelles nous pouvons dessiner et qui peuvent être envoyées à la fenêtre. Dans le prochain chapitre, nous verrons comment utiliser ces images comme cibles de rendu, puis nous verrons le pipeline graphique et les commandes d'affichage !
IV-B-3. Vues d’image▲
Afin d’utiliser, dans le pipeline de rendu, n’importe quelle image (VkImage), notamment celles provenant de la « swap chain », nous devons créer une vue (VkImageView). Cette vue est littéralement une vue dans l'image. Elle décrit comment accéder à l’image et quelle partie accéder. Par exemple, elle indique si elle doit être traitée comme une texture de profondeur 2D sans aucun niveau de mipmapping.
Dans ce chapitre, nous écrirons une fonction createImageViews() pour créer une vue pour chaque image de « swap chain ». Ainsi, nous pourrons les utiliser comme cibles pour les couleurs plus tard.
Ajoutez d'abord un membre à la classe pour y stocker les vues :
std::vector<VkImageView> swapChainImageViews;Créez la fonction createImageViews() et appelez-la juste après la création de la « swap chain ».
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
}
void createImageViews() {
}Nous devons d'abord redimensionner la liste pour pouvoir y mettre toutes les vues que nous créerons :
void createImageViews() {
swapChainImageViews.resize(swapChainImages.size());
}Ensuite, insérez la boucle qui parcourra toutes les images de la « swap chain. ».
for (size_t i = 0; i < swapChainImages.size(); i++) {
}La structure VkImageViewCreateInfo permet d’indiquer les paramètres pour la création des vues. Les premiers paramètres sont assez simples :
VkImageViewCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_IMAGE_VIEW_CREATE_INFO;
createInfo.image = swapChainImages[i];Les propriétés viewType et format indiquent la manière dont les données de l’image doivent être interprétées. Le paramètre viewType permet de traiter les images comme des textures 1D, 2D, 3D ou des cube maps.
createInfo.viewType = VK_IMAGE_VIEW_TYPE_2D;
createInfo.format = swapChainImageFormat;La propriété components vous permet de réorganiser les canaux de couleur. Par exemple, vous pouvez envoyer tous les canaux au canal rouge pour obtenir une texture monochrome. Vous pouvez aussi utiliser des valeurs constantes entre 0 et 1 à un canal. Dans notre cas nous garderons les paramètres par défaut.
createInfo.components.r = VK_COMPONENT_SWIZZLE_IDENTITY;
createInfo.components.g = VK_COMPONENT_SWIZZLE_IDENTITY;
createInfo.components.b = VK_COMPONENT_SWIZZLE_IDENTITY;
createInfo.components.a = VK_COMPONENT_SWIZZLE_IDENTITY;La propriété subresourceRange décrit le but de l’image et quelle partie doit être accédée. Notre image sera utilisée comme cible de couleur et n'aura ni mipmapping ni plusieurs couches.
createInfo.subresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
createInfo.subresourceRange.baseMipLevel = 0;
createInfo.subresourceRange.levelCount = 1;
createInfo.subresourceRange.baseArrayLayer = 0;
createInfo.subresourceRange.layerCount = 1;Si vous travailliez sur une application 3D stéréoscopique, vous devriez alors créer une « swap chain » avec plusieurs couches. Vous pourriez alors créer plusieurs vues pour chaque image et utiliser les couches pour accéder à ce qui sera affiché pour l’œil gauche et l’œil droit.
Il ne reste plus qu’à appeler la fonction vkCreateImageView() pour créer la vue :
if (vkCreateImageView(device, &createInfo, nullptr, &swapChainImageViews[i]) != VK_SUCCESS) {
throw std::runtime_error("Échec de création des vues d’image !");
}À la différence des images, nous avons créé les vues nous-mêmes et nous devons donc les détruire grâce à une boucle :
void cleanup() {
for (auto imageView : swapChainImageViews) {
vkDestroyImageView(device, imageView, nullptr);
}
...
}Une vue suffit pour commencer à utiliser une image comme une texture, mais pas pour que l'image soit utilisée comme cible de rendu. Pour cela, nous avons encore une étape, appelée tampon d’image. Mais d’abord, nous devons mettre en place le pipeline graphique.
IV-C. Bases du pipeline graphique▲
IV-C-1. Introduction▲
Dans les chapitres qui suivent, nous allons configurer un pipeline graphique pour dessiner notre premier triangle. Le pipeline graphique est l'ensemble des opérations qui, à partir des sommets et des textures de vos éléments, produisent les pixels qui sont écrits dans les cibles de rendu. En voici, un résumé simplifié :
![[ALT-PASTOUCHE]](./images/vulkan_simplified_pipeline.svg)
L’assembleur des entrées (input assembler) collecte les données brutes des sommets à partir des tampons que vous avez configurés. Il est aussi possible d’utiliser un tampon d’indices pour répéter certains éléments sans avoir à les dupliquer dans les tampons.
Le vertex shader est exécuté pour chaque sommet. Généralement, il effectue des transformations pour que les coordonnées des sommets passent de l'espace modèle (model space) à l'espace écran (screen space). Il peut aussi transférer des données à la suite du pipeline.
Les tesselation shaders permettent de subdiviser la géométrie selon des règles paramétrables afin d'améliorer la qualité du modèle. Ce procédé est notamment utilisé pour augmenter le relief de certaines surfaces comme les murs de briques ou les escaliers.
Le geometry shader est exécuté pour chaque primitive (triangle, ligne, points…). Il peut en supprimer ou en créer à la volée. Ce travail est similaire à celui du tesselation shader tout en étant beaucoup plus flexible. Il n'est cependant pas beaucoup utilisé à cause de ses performances médiocres (sauf avec les GPU intégrés d'Intel).
L’étage de rastérisation (ou matricialisation) transforme les primitives en fragments. Pour cela, la carte graphique détermine les pixels du tampon d’image (framebuffer) qui sont à l’intérieur des primitives. Tout fragment en dehors de l'écran est abandonné. Les attributs sortant du vertex shader sont interpolés pour déterminer les valeurs propres aux fragments. Les fragments cachés par d'autres fragments peuvent être éliminés à cette étape grâce au test de profondeur (depth testing).
Le fragment shader est exécuté pour chaque fragment valide et détermine dans quel tampon d’image écrire. Le fragment shader détermine aussi quelle couleur et quelle valeur de profondeur écrire. Il réalise ce travail à l'aide des données interpolées émises par le vertex shader, notamment les coordonnées de texture et les normales permettant d’effectuer les calculs d'éclairage.
L’étape de mélange des couleurs (color blending) applique des opérations pour mixer différents fragments correspondant à un même pixel sur le tampon d’image. Les fragments peuvent écraser les valeurs précédentes, s’additionner ou se mélanger selon leur transparence.
Les étapes en vert sur le diagramme sont des étapes fixes. Il est possible d’en modifier les paramètres influençant les calculs, mais pas de modifier les calculs eux-mêmes.
Les étapes colorées en orange sont programmables, ce qui signifie que vous pouvez charger votre propre code dans la carte graphique et faire exactement ce que vous voulez. Par exemple, vous pouvez utiliser les fragment shaders pour implémenter n'importe quoi : utiliser des textures, mettre en place les effets de lumières ou encore, faire du lancer de rayon (ray tracing). Ces programmes sont exécutés en parallèle sur de nombreux cœurs pour traiter de nombreux modèles, sommets et fragments rapidement.
Si vous avez utilisé d'anciennes bibliothèques comme OpenGL ou Direct3D, vous êtes habitués à pouvoir changer les paramètres du pipeline à tout moment, avec des fonctions comme glBlendFunc() ou OMSSetBlendState(). Cela n'est plus possible avec Vulkan. Le pipeline graphique y est quasiment fixé et vous devrez en recréer un si vous voulez changer de shader, y attacher différents tampons d’image ou changer la fonction de mélange des couleurs. Le désavantage est qu’il est maintenant nécessaire de créer un grand nombre de pipelines afin de gérer toutes les combinaisons d’états que vous souhaitez utiliser. Par contre, comme le pilote connaît à l’avance tous les pipelines possibles, il peut donc effectuer de meilleures optimisations.
Certaines étapes programmables sont optionnelles suivant ce que vous voulez faire. Par exemple, la tesselation et le geometry shader peuvent être désactivés lorsque vous dessinez des géométries simples. Si vous n'êtes intéressé que par les valeurs de profondeur, vous pouvez désactiver le fragment shader, ce qui est utile pour créer les textures d’ombre.
Dans le prochain chapitre, nous allons d'abord créer les deux éléments nécessaires à l'affichage d'un triangle à l'écran : le vertex shader et le fragment shader. Les étapes fixes seront mises en place dans le chapitre d’après. La dernière préparation nécessaire à la mise en place du pipeline graphique Vulkan sera de fournir les tampons d’image en entrée et sortie.
Créez la fonction createGraphicsPipeline() et appelez-la depuis initVulkan() après l’appel à la fonction createImageViews(). Nous travaillerons sur cette fonction dans les chapitres suivants.
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createGraphicsPipeline();
}
...
void createGraphicsPipeline() {
}IV-C-2. Module de shaders▲
À la différence des bibliothèques précédentes, le code des shaders doit être fourni à Vulkan sous la forme d’un code intermédiaire (bytecode) et non sous une forme facilement compréhensible par l'homme, tel que le GLSL ou le HLSL. Ce code intermédiaire est appelé SPIR-V, il est conçu pour fonctionner avec Vulkan et OpenCL (deux bibliothèques de Khronos). Le code SPIR-V peut servir à écrire des shaders pour les graphiques ou pour du calcul. Évidemment, dans ce tutoriel, nous nous concentrerons sur les shaders à destination du pipeline graphique de Vulkan.
L'avantage d’utiliser un code intermédiaire est de réduire la complexité du code d’interprétation des shaders des pilotes graphiques. En effet, les constructeurs ne proposaient pas la même interprétation du langage GLSL. Par conséquent, il était possible d’écrire du code fonctionnant sur les cartes d’un constructeur donné, mais pour lequel vous obteniez des erreurs de syntaxe avec d’autres constructeurs. Pire, vous pouviez avoir des comportements différents. Avec un format de code intermédiaire comme le SPIR-V, ces problèmes tendent à être évités.
Cependant, cela ne veut pas dire que nous devrons écrire ce code intermédiaire à la main. Khronos a même fourni son propre compilateur, indépendant des constructeurs, permettant de transformer le GLSL en SPIR-V. Ce compilateur standard vérifie que votre code correspond à la spécification et produit un binaire SPIR-V à embarquer dans votre programme. Vous pouvez également l'inclure comme une bibliothèque pour produire du SPIR-V au cours de l’exécution du programme. Mais nous ne le ferons pas dans ce tutoriel. Le compilateur de Khronos s’appelle glslangValidator, mais nous allons utiliser glslc qui lui est développé par Google. L'avantage de ce dernier est qu'il utilise des paramètres semblables aux compilateurs GCC et Clang tout en ajoutant quelques fonctionnalités comme les inclusions. Les deux compilateurs sont présents dans le SDK, vous n'avez donc rien de plus à télécharger.
Le GLSL est un langage possédant une syntaxe proche du C. Les programmes doivent posséder une fonction main(), invoquée pour chaque objet à traiter. Plutôt que d'utiliser des paramètres et des valeurs de retour, le GLSL utilise des variables globales pour les entrées et les sorties. Le langage possède des fonctionnalités spécifiques à la programmation graphique, telles que des primitives pour les vecteurs et les matrices. De plus, le langage fournit les fonctions pour réaliser des produits en croix, des multiplications de matrices ainsi que des fonctionnalités de manipulation de vecteurs. Le vecteur est implémenté grâce aux types vec, suivi par un chiffre indiquant le nombre d’éléments compris dans celui-ci. Par exemple, pour une position 3D, nous utiliserons le type vec3. Il est possible d’accéder à chacun des éléments du vecteur comme on le ferait avec une structure. Par exemple, pour la coordonnée sur l’axe des X, on utilise .x. Il est aussi possible de créer un nouveau vecteur à partir de plusieurs composants d’un autre vecteur en une fois. Plus précisément, l’expression vec3(1.0, 2.0, 3.0).xy permet d’obtenir un vec2. Les constructeurs des vecteurs peuvent aussi bien accepter des vecteurs que des valeurs scalaires. Par exemple, vous pouvez construire un vec3 avec la syntaxe vec3(vec2(1.0, 2.0), 3.0).
Comme nous l'avons dit au chapitre précédent, nous devons écrire un vertex shader et un fragment shader pour pouvoir afficher un triangle à l'écran. Les deux prochaines sections couvriront ce travail, puis nous verrons comment créer les binaires SPIR-V correspondants et les charger dans le programme.
IV-C-2-a. Le vertex shader▲
Le vertex shader traite chaque sommet fourni en entrée. Il récupère des attributs telles la position, la couleur, la normale ou les coordonnées de texture. En sortie, le vertex shader fournit une position en coordonnées dans l’espace de clipping et les attributs à envoyer au fragment shader telles que la couleur ou les coordonnées de texture. Ces valeurs seront interpolées lors de la rastérisation afin de produire un dégradé continu, puis elles seront passées au fragment shader.
Une coordonnée dans l’espace de clipping est un vecteur à quatre éléments émis par le vertex shader. Il est ensuite transformé en une coordonnée normalisée grâce à la division de ses composants par le dernier d’entre eux. Les coordonnées normalisées sont des coordonnées homogènes qui s’étalent sur le tampon d’image grâce à un système de coordonnées compris dans l’intervalle [-1, 1]. Il ressemble à cela :
![[ALT-PASTOUCHE]](./images/normalized_device_coordinates.svg)
Vous devriez déjà être familier avec ces notions si vous avez déjà manipulé des graphismes 3D. Si vous avez utilisé OpenGL avant, vous vous rendrez compte que l'axe Y est maintenant inversé et que l'axe Z va de 0 à 1, comme avec Direct3D.
Pour notre premier triangle, nous n'appliquerons aucune transformation, nous nous contenterons de spécifier directement les coordonnées normalisées des trois sommets pour créer la forme suivante :
![[ALT-PASTOUCHE]](./images/triangle_coordinates.svg)
Nous pouvons directement envoyer des coordonnées normalisées en tant que coordonnées dans l’espace de découpage en assignant le dernier composant à 1. Ainsi, la division transformant les coordonnées dans l’espace de découpage en coordonnées normalisées ne modifie pas les valeurs.
Normalement, ces coordonnées proviennent d’un tampon de sommets, mais la création et le remplissage de ce dernier ne sont pas des opérations triviales avec Vulkan. J'ai donc décidé de retarder ce sujet afin d'obtenir un résultat satisfaisant plus rapidement. Par conséquent, nous allons faire quelque chose de peu orthodoxe en attendant : inclure les coordonnées directement dans le vertex shader. Son code ressemble donc à ceci :
#version 450
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
}La fonction main() est appelée pour chaque sommet. La variable prédéfinie gl_VertexIndex contient l'indice du sommet en cours de traitement. Généralement, c’est l’indice du tampon de sommets, mais dans ce cas, nous l’utilisons comme indice pour nos données en dur. La position de chaque sommet est récupérée à partir du tableau constant du shader et complétée avec des valeurs factices pour produire les coordonnées dans l’espace de découpage. La variable gl_Position correspond à la sortie.
IV-C-2-b. Le fragment shader▲
Le triangle formé par les positions émises par le vertex shader colorie une zone de l’écran grâce aux nombreux fragments compris dedans. Le fragment shader est invoqué pour chacun d'entre eux et produit une couleur et une profondeur pour le tampon d’image (ou les tampons d’image). Un fragment shader dont le but est de renvoyer la couleur rouge pour l’intégralité de l’écran s’écrit ainsi :
#version 450
#extension GL_ARB_separate_shader_objects : enable
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(1.0, 0.0, 0.0, 1.0);
}La fonction main() est appelée pour chaque fragment de la même manière que le vertex shader est appelé pour chaque sommet. Les couleurs sont des vecteurs de quatre composants : R, G, B et le canal alpha. Les valeurs sont comprises dans l’intervalle [0, 1]. Au contraire de gl_Position, il n'y a pas de variable prédéfinie dans laquelle écrire la valeur de la couleur. Vous devrez spécifier votre propre variable de sortie pour chaque tampon d’image. La syntaxe layout(location = 0) indique l'indice du tampon d’image où la couleur sera écrite. Ici, la couleur rouge est écrite dans la variable outColor liée au premier (et unique) tampon d’image ayant pour indice 0.
IV-C-2-c. Une couleur pour chaque sommet▲
Avoir un triangle complètement rouge n’est pas vraiment intéressant. N’aimeriez-vous pas avoir un triangle comme celui-ci ?
![[ALT-PASTOUCHE]](./images/triangle_coordinates_colors.png)
Nous devons pour cela faire quelques petits changements aux deux shaders. Spécifions d'abord une couleur distincte pour chaque sommet. Le vertex shader doit donc embarquer un tableau avec les couleurs, tout comme cela a été fait pour les positions :
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);Nous devons maintenant envoyer ces couleurs au fragment shader afin qu'il puisse écrire les valeurs interpolées dans le tampon d’image. Ajoutez une variable de sortie au vertex shader pour la couleur et définissez sa valeur dans la fonction main() :
layout(location = 0) out vec3 fragColor;
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}Nous devons ensuite ajouter l'entrée correspondante dans le fragment shader :
layout(location = 0) in vec3 fragColor;
void main() {
outColor = vec4(fragColor, 1.0);
}La variable d’entrée n’a pas besoin d’avoir le même nom. Les sorties du vertex shader et les entrées du fragment shader sont liées par les indices spécifiés dans les directives location. La fonction main() doit être modifiée pour émettre la couleur provenant du vertex shader tout en lui ajoutant un canal alpha. Les valeurs de fragColor sont automatiquement interpolées pour obtenir les valeurs des fragments entre les trois sommets. Ainsi, et comme le montre l’image précédente, cela donne un dégradé uniforme.
IV-C-2-d. Compilation des shaders▲
Créez un dossier shaders à la racine de votre projet et enregistrez-y le vertex shader dans un fichier appelé shader.vert et le fragment shader dans un fichier appelé shader.frag. Les shaders en GLSL n'ont pas d'extension officielle, mais celles-ci sont habituellement utilisées pour les reconnaître.
Le contenu de shader.vert devrait être :
#version 450
#extension GL_ARB_separate_shader_objects : enable
out gl_PerVertex {
vec4 gl_Position;
};
layout(location = 0) out vec3 fragColor;
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}Et shader.frag devrait contenir :
#version 450
#extension GL_ARB_separate_shader_objects : enable
layout(location = 0) in vec3 fragColor;
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(fragColor, 1.0);
}Nous allons maintenant compiler ces shaders en code intermédiaire SPIR-V à l'aide du programme glslc.
IV-C-2-d-i. Windows▲
Créez un fichier compile.bat et copiez ceci dedans :
C:/VulkanSDK/x.x.x.x/Bin32/glslc.exe shader.vert -o vert.spv
C:/VulkanSDK/x.x.x.x/Bin32/glslc.exe shader.frag -o frag.spv
pauseCorrigez le chemin menant à glslc.exe avec le chemin où vous avez installé le SDK Vulkan. Double-cliquez dessus pour lancer ce script.
IV-C-2-d-ii. Linux▲
Créez un fichier compile.sh et copiez ceci dedans :
/home/user/VulkanSDK/x.x.x.x/x86_64/bin/glslc shader.vert -o vert.spv
/home/user/VulkanSDK/x.x.x.x/x86_64/bin/glslc shader.frag -o frag.spvCorrigez le chemin menant à glslc pour correspondre au chemin de votre installation du SDK Vulkan. Rendez le script exécutable avec la commande chmod +x compile.sh et lancez-le.
IV-C-2-d-iii. Notes▲
Ces deux commandes demandent au compilateur de lire le code GLSL source contenu dans un fichier et d'écrire le code SPIR-V correspondant dans un fichier grâce à l'option -o (output).
Si votre shader contient une erreur de syntaxe, le compilateur vous indiquera la ligne et le problème, comme vous pouvez vous y attendre. Essayez de retirer un point-virgule et relancez le script. Aussi, essayez de lancer le compilateur sans arguments afin de voir la liste des options supportées. Par exemple, il est possible de produire un code intermédiaire lisible par un humain afin de comprendre exactement ce que fait le shader et les optimisations qui y ont été appliquées.
La compilation des shaders en ligne de commande est l'une des solutions les plus simples et c’est celle que nous utilisons dans ce tutoriel. Il est aussi possible de compiler les shaders dans votre code. Le SDK Vulkan inclut la bibliothèque libshaderc permettant de compiler le GLSL en SPIR-V directement depuis votre programme.
IV-C-2-e. Charger un shader▲
Maintenant que vous pouvez créer des shaders SPIR-V, il est temps de les charger dans le programme et de les intégrer au pipeline graphique. Nous allons d'abord écrire une fonction qui réalisera le chargement des données binaires à partir des fichiers.
#include <fstream>
...
static std::vector<char> readFile(const std::string& filename) {
std::ifstream file(filename, std::ios::ate | std::ios::binary);
if (!file.is_open()) {
throw std::runtime_error("Échec d’ouverture du fichier !");
}
}La fonction readFile() lira tous les octets du fichier spécifié et les retournera dans un tableau d’octets géré par std::vector. Nous spécifions les deux options suivantes lors de l'ouverture du fichier :
- ate: permet de commencer la lecture à la fin du fichier ;
- binary : indique que le fichier lu est binaire (pour éviter les transformations spécifiques au texte).
En commençant la lecture par la fin du fichier, il est possible d’utiliser la position pour récupérer la taille du fichier pour allouer le tampon :
size_t fileSize = (size_t) file.tellg();
std::vector<char> buffer(fileSize);Après cela, nous revenons au début du fichier et lisons tous les octets en une fois :
file.seekg(0);
file.read(buffer.data(), fileSize);Enfin, nous pouvons fermer le fichier et renvoyer les octets :
file.close();
return buffer;Appelons maintenant cette fonction depuis la fonction createGraphicsPipeline() pour charger le code intermédiaire des deux shaders :
void createGraphicsPipeline() {
auto vertShaderCode = readFile("shaders/vert.spv");
auto fragShaderCode = readFile("shaders/frag.spv");
}Assurez-vous que les shaders sont correctement chargés en affichant la taille des fichiers lus depuis votre programme, puis en comparant cette valeur à la taille des fichiers indiquée par le système d’exploitation. Notez que le code n'a pas besoin d’utiliser un terminateur, car c’est du code binaire et que nous allons indiquer sa taille.
IV-C-2-f. Créer des modules de shader▲
Avant de passer ce code au pipeline, nous devons l’incorporer dans un objet VkShaderModule. Créez pour cela une fonction nommée createShaderModule.
VkShaderModule createShaderModule(const std::vector<char>& code) {
}Cette fonction prendra comme paramètre le tampon contenant le code intermédiaire et créera un VkShaderModule à partir de celui-ci.
La création d'un module de shader est simple. Nous devons simplement indiquer un pointeur vers le tampon et la taille de celui-ci. Ces informations seront inscrites dans la structure VkShaderModuleCreateInfo. Le seul problème est que la taille du code intermédiaire doit être en octets, mais le pointeur sur le code intermédiaire est du type uint32_t et non du type char. Nous devons donc utiliser reinterpet_cast sur notre pointeur. Lors d’une telle transcription de pointeur, il faut s’assurer que les données sont compatibles avec l’alignement nécessaire pour uint32_t. Heureusement pour nous, l’allocateur par défaut d’un std::vector assure que les données stockées remplissent les conditions, même dans les pires cas.
VkShaderModuleCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO;
createInfo.codeSize = code.size();
createInfo.pCode = reinterpret_cast<const uint32_t*>(code.data());L’objet VkShaderModule peut alors être créé en appelant la fonction vkCreateShaderModule() :
VkShaderModule shaderModule;
if (vkCreateShaderModule(device, &createInfo, nullptr, &shaderModule) != VK_SUCCESS) {
throw std::runtime_error("Échec de création du module de shader !");
}Les paramètres sont les mêmes que pour la création des objets précédents : le périphérique logique, le pointeur sur la structure contenant les informations, un pointeur optionnel vers l'allocateur et une référence pour stocker l’objet créé. Le tampon contenant le code peut être libéré immédiatement après la création du module. Enfin, renvoyez le module de shader créé :
return shaderModule;Les modules de shader ne sont réellement qu'une fine couche autour du code intermédiaire chargé depuis les fichiers. La compilation et la liaison du code intermédiaire SPIR-V vers un code machine prêt à être exécuté par le GPU ne se font qu’au moment de la création du pipeline graphique. Cela signifie que vous pouvez détruire les modules de shader dès que la création du pipeline est finie. Pour cette raison, nous gardons les modules dans des variables locales dans la fonction createGraphicsPipeline() :
void createGraphicsPipeline() {
auto vertShaderCode = readFile("shaders/vert.spv");
auto fragShaderCode = readFile("shaders/frag.spv");
VkShaderModule vertShaderModule = createShaderModule(vertShaderCode);
VkShaderModule fragShaderModule = createShaderModule(fragShaderCode);La libération doit être placée à la fin de la fonction grâce à deux appels à la fonction vkDestroyShaderModule(). Le reste du code de ce chapitre sera à ajouter avant ces deux lignes.
...
vkDestroyShaderModule(device, fragShaderModule, nullptr);
vkDestroyShaderModule(device, vertShaderModule, nullptr);
}IV-C-2-g. Création des étapes programmables▲
Pour utiliser les shaders, nous devons les assigner à l’étape programmable du pipeline grâce à la structure VkPipelineShaderStageCreateInfo. Cette structure fait partie du processus de création du pipeline.
Nous allons d'abord remplir cette structure pour le vertex shader. Nous le faisons dans la fonction createGraphicsPipeline().
VkPipelineShaderStageCreateInfo vertShaderStageInfo{};
vertShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
vertShaderStageInfo.stage = VK_SHADER_STAGE_VERTEX_BIT;La première étape, sans compter la propriété sType, consiste à dire à Vulkan dans quelle étape le shader sera utilisé. Il existe une énumération décrivant les étapes vues dans le chapitre précédent.
vertShaderStageInfo.module = vertShaderModule;
vertShaderStageInfo.pName = "main";Les deux propriétés suivantes indiquent le module contenant le code et la fonction à invoquer : le point d’entrée. Il est donc possible de combiner plusieurs fragment shaders dans un même module et les différencier à l'aide de leurs points d'entrée. Dans notre cas, nous nous contenterons de la fonction main() classique.
Il existe un autre membre, optionnel, appelé pSpecializationInfo, que nous n'utiliserons pas, mais qu'il est intéressant d'évoquer. Il vous permet de spécifier les valeurs des constantes du shader. Vous pouvez utiliser un seul module de shader et modifier son comportement à l’aide de constantes définies lors de la création du pipeline. C’est plus efficace que d’utiliser des variables définies lors du rendu, car le compilateur peut ainsi effectuer des optimisations, notamment supprimer les blocs d’un if inutilisés. Si vous n’avez pas de constante, alors vous pouvez définir ce membre à nullptr, valeur déjà définie par l’initialisation de la structure.
La modification de la structure pour la faire correspondre au fragment shader est simple :
VkPipelineShaderStageCreateInfo fragShaderStageInfo{};
fragShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
fragShaderStageInfo.stage = VK_SHADER_STAGE_FRAGMENT_BIT;
fragShaderStageInfo.module = fragShaderModule;
fragShaderStageInfo.pName = "main";Enfin, définissez un tableau contenant ces deux structures. Nous les utiliserons lors de la création du pipeline.
VkPipelineShaderStageCreateInfo shaderStages[] = {vertShaderStageInfo, fragShaderStageInfo};Nous avons vu comment configurer les étapes programmables du pipeline. Dans le prochain chapitre, nous verrons les étapes fixes.
IV-C-3. Étapes fixes▲
Les anciennes bibliothèques définissaient des configurations par défaut pour la plupart des étapes du pipeline graphique. Avec Vulkan, vous devez décrire l’intégralité du pipeline, du viewport aux fonctions de mélange de couleurs. Dans ce chapitre, nous remplirons toutes les structures nécessaires à la configuration des fonctionnalités fixes.
IV-C-3-a. Les sommets en entrée▲
La structure VkPipelineVertexInputStateCreateInfo décrit le format des données des sommets envoyés au vertex shader. Globalement, cela se fait en deux étapes :
- liens (bindings) : espacement entre les données et indication permettant de savoir si les données sont par sommet ou par instance (pour l'instanciation) ;
- descriptions des attributs : décrit le type des attributs passés au vertex shader, à partir de quel lien charger les données et à quelle position (offset).
Pour le moment et comme nous avons écrit en dur les données des sommets dans le vertex shader, nous allons remplir cette structure pour indiquer qu’il n’y a pas de données de sommets. Nous reviendrons sur cette structure dans le chapitre sur les tampons de sommets.
VkPipelineVertexInputStateCreateInfo vertexInputInfo{};
vertexInputInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_VERTEX_INPUT_STATE_CREATE_INFO;
vertexInputInfo.vertexBindingDescriptionCount = 0;
vertexInputInfo.pVertexBindingDescriptions = nullptr; // Optionnel
vertexInputInfo.vertexAttributeDescriptionCount = 0;
vertexInputInfo.pVertexAttributeDescriptions = nullptr; // OptionnelLes membres pVertexBindingDescriptions et pVertexAttributeDescriptions pointent vers un tableau de structures décrivant les détails du chargement des données des sommets. Ajoutez cette structure à la fonction createGraphicsPipeline() juste après le tableau shaderStages.
IV-C-3-b. Assembleur d’entrée▲
La structure VkPipelineInputAssemblyStateCreateInfo décrit deux choses : quel type de géométrie dessiner et si la réévaluation des sommets doit être activée. La première information est décrite dans le membre topology et peut prendre ces valeurs :
- VK_PRIMITIVE_TOPOLOGY_POINT_LIST : chaque sommet correspond à un point ;
- VK_PRIMITIVE_TOPOLOGY_LINE_LIST : dessine une ligne en utilisant les sommets deux par deux ;
- VK_PRIMITIVE_TOPOLOGY_LINE_STRIP : le dernier sommet de chaque ligne est utilisé comme premier sommet pour la ligne suivante ;
- VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST : dessine un triangle en utilisant les sommets trois par trois ;
- VK_PRIMITIVE_TOPOLOGY_TRIANGLE_STRIP : les deuxième et troisième sommets sont utilisés comme les deux premiers pour le triangle suivant.
Normalement, les sommets sont chargés en utilisant les indices séquentiellement depuis le tampon de sommets. En utilisant un tampon d’éléments, vous pouvez spécifier vous-même les indices. Vous pouvez ainsi réaliser des optimisations, notamment en réutilisant les sommets plusieurs fois. Si vous mettez le membre primitiveRestartEnable à la valeur VK_TRUE, il devient alors possible d'interrompre les lignes ou triangles lors de l’utilisation d’un mode _STRIP grâce aux valeurs 0xFFFF ou 0xFFFFFFFF.
Nous n'afficherons que des triangles dans ce tutoriel, nous nous contenterons donc de remplir la structure de cette manière :
VkPipelineInputAssemblyStateCreateInfo inputAssembly{};
inputAssembly.sType = VK_STRUCTURE_TYPE_PIPELINE_INPUT_ASSEMBLY_STATE_CREATE_INFO;
inputAssembly.topology = VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST;
inputAssembly.primitiveRestartEnable = VK_FALSE;IV-C-3-c. Viewports et découpage▲
Un viewport décrit la région d'un tampon d’image sur laquelle le rendu sera effectué. Généralement, il démarre de (0, 0) et a une taille correspondant à la largeur et la hauteur de l’image. Cela est le cas dans ce tutoriel.
VkViewport viewport{};
viewport.x = 0.0f;
viewport.y = 0.0f;
viewport.width = (float) swapChainExtent.width;
viewport.height = (float) swapChainExtent.height;
viewport.minDepth = 0.0f;
viewport.maxDepth = 1.0f;N'oubliez pas que la taille des images de la « swap chain » peut différer de celle des macros WIDTH et HEIGHT. Les images de la « swap chain » seront utilisées comme tampon d’image plus tard, nous devons donc utiliser leur taille.
Les valeurs minDepth et maxDepth indiquent les valeurs minimales et maximales pour la profondeur dans le tampon d’image. Ces valeurs doivent être comprises dans l’intervalle [0.0f, 1.0f],mais minDepth peut être supérieure à maxDepth. Si vous ne faites rien de particulier, contentez-vous des valeurs classiques 0.0f et 1.0f.
Alors que les viewports définissent la transformation de l'image vers le tampon d’image, les rectangles de découpage (scissors) définissent la région de pixels qui sera conservée. Tout pixel en dehors de ces rectangles sera éliminé par le rastériseur. Leur fonctionnement ressemble plus à un filtre qu’à une transformation. La différence est montrée ci-dessous. Notez que le rectangle de découpage pour l’image de gauche est l’une des possibilités permettant d’obtenir une telle image. L’image sera la même tant que le rectangle est plus grand que le viewport.
![[ALT-PASTOUCHE]](./images/viewports_scissors.png)
Dans ce tutoriel, nous voulons dessiner sur la totalité du tampon d’image. Nous utilisons donc un rectangle de découpage couvrant l’intégralité du tampon d’image :
VkRect2D scissor{};
scissor.offset = {0, 0};
scissor.extent = swapChainExtent;Le viewport et le rectangle de découpage se combinent en un état de viewport à l'aide de la structure VkPipelineViewportStateCreateInfo. Sur certaines cartes graphiques, il est possible d'utiliser plusieurs viewports et rectangles de découpage. C'est pourquoi la structure accepte des tableaux pour ces deux données. L'utilisation de cette possibilité nécessite de l'activer lors de la création du périphérique logique.
VkPipelineViewportStateCreateInfo viewportState{};
viewportState.sType = VK_STRUCTURE_TYPE_PIPELINE_VIEWPORT_STATE_CREATE_INFO;
viewportState.viewportCount = 1;
viewportState.pViewports = &viewport;
viewportState.scissorCount = 1;
viewportState.pScissors = &scissor;IV-C-3-d. Rastériseur▲
Le rastériseur récupère la géométrie formée par des sommets provenant du vertex shader et les transforme en fragments qui seront traités par le fragment shader. Il réalise également le test de profondeur, la suppression des faces et le test de découpage et peut être configuré pour retourner des fragments couvrant l’intégralité de la géométrie ou juste les bords (rendu en fil de fer). Tout cela se configure dans la structure VkPipelineRasterizationStateCreateInfo.
VkPipelineRasterizationStateCreateInfo rasterizer{};
rasterizer.sType = VK_STRUCTURE_TYPE_PIPELINE_RASTERIZATION_STATE_CREATE_INFO;
rasterizer.depthClampEnable = VK_FALSE;Si le membre depthClampEnable est VK_TRUE, les fragments au-delà des plans proche et lointain sont fixés aux valeurs des plans et non plus supprimés. Cela peut être pratique lors du rendu des textures d’ombrage (shadow maps). Cette fonctionnalité nécessite d’activer une fonctionnalité du GPU.
rasterizer.rasterizerDiscardEnable = VK_FALSE;Si le membre rasterizerDiscardEnable est VK_TRUE, aucune géométrie ne passe l'étape du rastériseur. En clair, cela désactive tout rendu dans le tampon d’image.
rasterizer.polygonMode = VK_POLYGON_MODE_FILe propriété polygonMode définit comment les fragments sont générés à partir de la géométrie. Vulkan vous donne accès aux modes suivants :
- VK_POLYGON_MODE_FILL : remplit les polygones de fragments ;
- VK_POLYGON_MODE_LINE : les côtés des polygones sont dessinés comme des lignes ;
- VK_POLYGON_MODE_POINT : les sommets des polygones sont dessinés comme des points.
Tout autre mode que FILL nécessite d’activer une fonctionnalité GPU.
rasterizer.lineWidth = 1.0f;La propriété lineWidth définit l’épaisseur des lignes en termes de fragments. La taille maximale supportée dépend du GPU et toute autre valeur que 1.0f nécessite l’activation de la fonctionnalité GPU wideLines.
rasterizer.cullMode = VK_CULL_MODE_BACK_BIT;
rasterizer.frontFace = VK_FRONT_FACE_CLOCKWISE;La propriété cullMode détermine quelles faces seront supprimées lors de l’étape de suppression des faces. Vous pouvez désactiver toute suppression, n'éliminer que les faces avant, que celles de derrière ou éliminer toutes les faces. La propriété frontFace indique l'ordre d'évaluation des sommets permettant de dire si la face est avant ou arrière : dans le sens des aiguilles d’une montre ou l’opposé.
rasterizer.depthBiasEnable = VK_FALSE;
rasterizer.depthBiasConstantFactor = 0.0f; // Optionnel
rasterizer.depthBiasClamp = 0.0f; // Optionnel
rasterizer.depthBiasSlopeFactor = 0.0f; // OptionnelLe rastériseur peut altérer la profondeur en y ajoutant une valeur constante ou en la modifiant selon l'inclinaison du fragment. Ces possibilités sont parfois exploitées pour la génération des textures d’ombrage, mais nous ne les utiliserons pas. Laissez depthBiasEnabled à la valeur VK_FALSE.
IV-C-3-e. Multiéchantillonnage▲
La structure VkPipelineMultisampleCreateInfo permet la configuration du multiéchantillonnage (multisampling), une des méthodes pour effectuer de l’anticrénelage (anti-aliasing). Cette méthode combine les résultats du fragment shader de plusieurs polygones dessinant le même pixel. Cela se produit notamment pour les bordures, endroit où le crénelage est le plus présent. Comme il n’est pas utile d’exécuter plusieurs fois le fragment shader lorsqu’il n’y a qu’un polygone associé à un pixel, c’est bien moins coûteux que d’effectuer un rendu de plus haute résolution et de le redimensionner. Activer le multiéchantillonnage nécessite l’activation d’une fonctionnalité GPU.
VkPipelineMultisampleStateCreateInfo multisampling{};
multisampling.sType = VK_STRUCTURE_TYPE_PIPELINE_MULTISAMPLE_STATE_CREATE_INFO;
multisampling.sampleShadingEnable = VK_FALSE;
multisampling.rasterizationSamples = VK_SAMPLE_COUNT_1_BIT;
multisampling.minSampleShading = 1.0f; // Optionnel
multisampling.pSampleMask = nullptr; // Optionnel
multisampling.alphaToCoverageEnable = VK_FALSE; // Optionnel
multisampling.alphaToOneEnable = VK_FALSE; // OptionnelNous reverrons le multisampling plus tard, pour l'instant laissez-le désactivé.
IV-C-3-f. Tests de profondeur et de pochoir▲
Si vous utilisez un tampon de profondeur (depth buffer) et/ou de pochoir (stencil buffer) vous devez configurer les tests de profondeur et de pochoir avec la structure VkPipelineDepthStencilStateCreateInfo. Nous n'avons aucun de ces tampons, donc nous indiquerons nullptr à la place du pointeur vers une telle structure. Nous y reviendrons au chapitre sur le tampon de profondeur.
IV-C-3-g. Mélange de couleurs▲
La couleur renvoyée par un fragment shader doit être combinée avec la couleur déjà présente dans le tampon d’image. Cette opération s'appelle mélange de couleurs (color blending) et peut être réalisée de deux façons :
- mélanger l'ancienne et la nouvelle couleur pour créer la couleur finale ;
- combiner l'ancienne et la nouvelle couleur à l'aide d'une opération bit à bit.
Il y a deux types de structures pour configurer le mélange de couleurs. La première, VkPipelineColorBlendAttachmentState, contient une configuration pour chaque tampon d’image et la seconde, VkPipelineColorBlendStateCreateInfo, contient les paramètres globaux pour le mélange de couleurs. Dans notre cas, nous n'avons qu'un tampon d’image :
VkPipelineColorBlendAttachmentState colorBlendAttachment{};
colorBlendAttachment.colorWriteMask = VK_COLOR_COMPONENT_R_BIT | VK_COLOR_COMPONENT_G_BIT | VK_COLOR_COMPONENT_B_BIT | VK_COLOR_COMPONENT_A_BIT;
colorBlendAttachment.blendEnable = VK_FALSE;
colorBlendAttachment.srcColorBlendFactor = VK_BLEND_FACTOR_ONE; // Optionnel
colorBlendAttachment.dstColorBlendFactor = VK_BLEND_FACTOR_ZERO; // Optionnel
colorBlendAttachment.colorBlendOp = VK_BLEND_OP_ADD; // Optionnel
colorBlendAttachment.srcAlphaBlendFactor = VK_BLEND_FACTOR_ONE; // Optionnel
colorBlendAttachment.dstAlphaBlendFactor = VK_BLEND_FACTOR_ZERO; // Optionnel
colorBlendAttachment.alphaBlendOp = VK_BLEND_OP_ADD; // OptionnelCette structure spécifique à chaque tampon d’image vous permet de configurer la première méthode pour effectuer un mélange de couleurs. L'opération effectuée ressemblera à ce pseudocode :
if (blendEnable) {
finalColor.rgb = (srcColorBlendFactor * newColor.rgb) <colorBlendOp> (dstColorBlendFactor * oldColor.rgb);
finalColor.a = (srcAlphaBlendFactor * newColor.a) <alphaBlendOp> (dstAlphaBlendFactor * oldColor.a);
} else {
finalColor = newColor;
}
finalColor = finalColor & colorWriteMask;Si blendEnable est VK_FALSE la nouvelle couleur du fragment shader est écrite telle qu’elle. Sinon, les deux opérations de mélange sont exécutées pour calculer la nouvelle couleur. Le résultat est combiné avec un ET binaire et la propriété colorWriteMask détermine quel canal est conservé.
L'utilisation la plus commune pour mélanger les couleurs est d’utiliser le canal alpha pour déterminer l'opacité du matériau et donc le mélange lui-même. La couleur finale devrait alors être calculée ainsi :
finalColor.rgb = newAlpha * newColor + (1 - newAlpha) * oldColor;
finalColor.a = newAlpha.a;Cela peut être réalisé avec les paramètres suivants :
colorBlendAttachment.blendEnable = VK_TRUE;
colorBlendAttachment.srcColorBlendFactor = VK_BLEND_FACTOR_SRC_ALPHA;
colorBlendAttachment.dstColorBlendFactor = VK_BLEND_FACTOR_ONE_MINUS_SRC_ALPHA;
colorBlendAttachment.colorBlendOp = VK_BLEND_OP_ADD;
colorBlendAttachment.srcAlphaBlendFactor = VK_BLEND_FACTOR_ONE;
colorBlendAttachment.dstAlphaBlendFactor = VK_BLEND_FACTOR_ZERO;
colorBlendAttachment.alphaBlendOp = VK_BLEND_OP_ADD;Vous pouvez trouver toutes les opérations possibles dans la spécification aux sections VkBlendFactor et VkBlendOp.
La seconde structure possède un tableau de structures pour tous les tampons d’image et vous permet de définir des valeurs constantes permettant d’altérer le calcul du mélange de couleurs vu précédemment.
VkPipelineColorBlendStateCreateInfo colorBlending{};
colorBlending.sType = VK_STRUCTURE_TYPE_PIPELINE_COLOR_BLEND_STATE_CREATE_INFO;
colorBlending.logicOpEnable = VK_FALSE;
colorBlending.logicOp = VK_LOGIC_OP_COPY; // Optionnel
colorBlending.attachmentCount = 1;
colorBlending.pAttachments = &colorBlendAttachment;
colorBlending.blendConstants[0] = 0.0f; // Optionnel
colorBlending.blendConstants[1] = 0.0f; // Optionnel
colorBlending.blendConstants[2] = 0.0f; // Optionnel
colorBlending.blendConstants[3] = 0.0f; // OptionnelSi vous voulez utiliser la seconde méthode de mélange de couleurs (la combinaison bit à bit), vous devez indiquer VK_TRUE au membre logicOpEnable. L’opération est spécifiée dans la propriété logicOp. En activant ce mode, la première méthode sera désactivée et vous devez mettre VK_FALSE dans tous les champs du tampon d’image attaché. La propriété colorWriteMask sera également utilisée dans ce mode pour déterminer les canaux affectés. Il est aussi possible de désactiver les deux modes comme nous l'avons fait ici. Dans ce cas, les résultats du fragment shader seront directement écrits dans le tampon d’image.
IV-C-3-h. États dynamiques▲
Un petit nombre d'états que nous avons spécifiés dans les structures précédentes peuvent être modifiés sans devoir recréer le pipeline. On y trouve la taille du viewport, la largeur des lignes et les constantes du mélange de couleurs. Pour cela, vous devrez remplir la structure VkPipelineDynamicStateCreateInfo comme suit :
VkDynamicState dynamicStates[] = {
VK_DYNAMIC_STATE_VIEWPORT,
VK_DYNAMIC_STATE_LINE_WIDTH
};
VkPipelineDynamicStateCreateInfo dynamicState{};
dynamicState.sType = VK_STRUCTURE_TYPE_PIPELINE_DYNAMIC_STATE_CREATE_INFO;
dynamicState.dynamicStateCount = 2;
dynamicState.pDynamicStates = dynamicStates;Les valeurs données lors de la configuration seront ignorées et vous devrez fournir les données nécessaires au moment du rendu. Nous y reviendrons plus tard. Cette structure peut être remplacée par nullptr si vous ne voulez pas utiliser d’état dynamique.
IV-C-3-i. Agencement du pipeline▲
Vous pouvez utiliser des variables uniformes dans les shaders : ce sont des données globales similaires aux états dynamiques que vous pouvez modifier lors du rendu pour modifier le comportement des shaders sans avoir à les recréer. Elles sont généralement utilisées pour passer les matrices de transformation au vertex shader ou pour créer les échantillonneurs de texture dans les fragment shader.
Les variables uniformes doivent être spécifiées lors de la création du pipeline en créant un objet VkPipelineLayout. Même si nous n'en utilisons pas dans nos shaders actuels, nous devons créer un agencement de pipeline vide.
Créez un membre pour stocker la structure, car nous en aurons besoin plus tard.
VkPipelineLayout pipelineLayout;Créons maintenant l'objet dans la fonction createGraphicsPipline() :
VkPipelineLayoutCreateInfo pipelineLayoutInfo{};
pipelineLayoutInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_LAYOUT_CREATE_INFO;
pipelineLayoutInfo.setLayoutCount = 0; // Optionnel
pipelineLayoutInfo.pSetLayouts = nullptr; // Optionnel
pipelineLayoutInfo.pushConstantRangeCount = 0; // Optionnel
pipelineLayoutInfo.pPushConstantRanges = nullptr; // Optionnel
if (vkCreatePipelineLayout(device, &pipelineLayoutInfo, nullptr, &pipelineLayout) != VK_SUCCESS) {
throw std::runtime_error("Échec lors de la création de l’agencement du pipeline !");
}Cette structure indique aussi les constantes poussées (push constants), une autre manière de passer des valeurs dynamiques aux shaders que nous verrons dans un futur chapitre. L’agencement du pipeline sera utilisé pendant toute la durée du programme, nous devons donc le détruire dans la fonction cleanup() :
void cleanup() {
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
...
}IV-C-3-j. Conclusion▲
Voilà tout ce qu'il y a à savoir sur les étapes fixes ! Leur configuration représente un gros travail, mais en contrepartie, nous connaissons l’intégralité de ce qui se passe dans le pipeline graphique ! Ainsi, les risques d’un comportement inattendu lié à une valeur par défaut d’une étape du pipeline sont diminués.
Il reste cependant encore un objet à créer avant de pouvoir créer le pipeline graphique : la passe de renduPasses de rendu.
IV-C-4. Passes de rendu▲
IV-C-4-a. Mise en place▲
Avant de finaliser la création du pipeline, nous devons indiquer à Vulkan les attaches au tampon d’image utilisées lors du rendu. Nous devons indiquer combien de tampons de couleurs et de profondeur il y aura et combien d’échantillons nous allons utiliser pour chacun d’eux, ainsi que la façon dont le contenu sera géré au travers des opérations de rendu. Toutes ces informations sont contenues dans un objet appelé passe de rendu (render pass) que nous allons créer dans une fonction createRenderPass(). Appelez cette fonction depuis initVulkan() avant createGraphicsPipeline().
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
}
...
void createRenderPass() {
}IV-C-4-b. Description de l'attache▲
Dans notre cas, nous n’aurons qu’une seule attache pour la couleur correspondant à une image provenant de la « swap chain ».
void createRenderPass() {
VkAttachmentDescription colorAttachment{};
colorAttachment.format = swapChainImageFormat;
colorAttachment.samples = VK_SAMPLE_COUNT_1_BIT;
}Le format de l’attache de couleur doit correspondre au format des images de la « swap chain ». Pour le moment, nous n'utilisons pas de multiéchantillonnage, donc, nous devons indiquer que nous n'utilisons qu'un seul échantillon.
colorAttachment.loadOp = VK_ATTACHMENT_LOAD_OP_CLEAR;
colorAttachment.storeOp = VK_ATTACHMENT_STORE_OP_STORE;Les propriétés loadOp et storeOp définissent respectivement ce qui doit être fait avec les données de l’attache avant et après le rendu. Pour loadOp, nous avons les choix suivants :
- VK_ATTACHMENT_LOAD_OP_LOAD : conserve les données présentes dans l’attache ;
- VK_ATTACHMENT_LOAD_OP_CLEAR : redéfinit, au commencement, les valeurs à une constante ;
- VK_ATTACHMENT_LOAD_OP_DONT_CARE : le contenu existant est non défini et nous n’en avons rien à faire.
Dans notre cas, nous utiliserons l'opération de remplacement pour obtenir un tampon d’image noir avant d'afficher une nouvelle image. Quant à storeOp, il existe deux possibilités :
- VK_ATTACHMENT_STORE_OP_STORE : le rendu est stocké en mémoire et peut être lu par la suite ;
- VK_ATTACHMENT_STORE_OP_DONT_CARE : le contenu du tampon d’image est indéfini après l’opération de rendu.
Comme nous voulons voir le triangle à l’écran, nous allons utiliser l’opération de stockage.
colorAttachment.stencilLoadOp = VK_ATTACHMENT_LOAD_OP_DONT_CARE;
colorAttachment.stencilStoreOp = VK_ATTACHMENT_STORE_OP_DONT_CARE;Les propriétés loadOp et storeOp s'appliquent aux données de couleur et de profondeur. De même, il existe les propriétés stencilLoadOp et stencilStoreOp pour les données de pochoir. Notre application n’utilise pas de tampon de pochoir, nous indiquons que les opérations de chargement et de sauvegarde ne nous sont pas utiles.
colorAttachment.initialLayout = VK_IMAGE_LAYOUT_UNDEFINED;
colorAttachment.finalLayout = VK_IMAGE_LAYOUT_PRESENT_SRC_KHR;Les textures et les tampons d’image dans Vulkan sont représentés par des objets de type VkImage comprenant un format de pixels donné. Cependant, l’agencement des pixels dans la mémoire peut changer selon ce que vous faites de cette image.
Les agencements les plus communs sont :
- VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL : images utilisées comme attache de couleur ;
- VK_IMAGE_LAYOUT_PRESENT_SRC_KHR : images qui seront envoyées à la « swap chain » ;
- VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL : images utilisées comme destination d'une opération de copie en mémoire.
Nous discuterons plus précisément de ce sujet dans le chapitre sur les textures. Pour le moment, il faut juste retenir que les images doivent avoir un agencement adéquat pour les opérations dans lesquelles elles seront utilisées.
La propriété initialLayout spécifie l'agencement de l'image avant le début de la passe de rendu. La propriété finalLayout indique l'agencement que l’image doit avoir à la fin de la passe de rendu. La propriété initialLayout peut avoir pour valeur VK_IMAGE_LAYOUT_UNDEFINED permettant de spécifier que l’agencement précédent ne nous intéresse pas. En contrepartie, il n’y a aucune garantie que le contenu de l’image soit conservé. Mais ce n'est pas un problème puisque, de toute façon, nous effaçons toutes les données avant le rendu. Après le rendu, nous souhaitons envoyer l’image à la « swap chain », nous utilisons donc VK_IMAGE_LAYOUT_PRESENT_SRC_KHR pour la propriété finalLayout.
IV-C-4-c. Sous-passes et références aux attaches▲
Une passe de rendu est composée de plusieurs sous-passes (subpasses). Les sous-passes sont des opérations de rendu qui dépendent du contenu présent dans le tampon d’image fourni par les passes précédentes. Un exemple concret est l’implémentation d’une série d’effets de post-traitement qui se suivent. En regroupant toutes ces opérations en une seule passe, Vulkan peut alors réorganiser les sous-passes, réduire l’utilisation de la bande passante et ainsi être plus performant. Pour notre premier triangle, nous nous contenterons d'une seule sous-passe.
Chaque sous-passe référence une ou plusieurs attaches que nous avons définies au travers des structures vues dans la section précédente. Ces références sont représentées par le type VkAttachmentReference et ressemblent à cela :
VkAttachmentReference colorAttachmentRef{};
colorAttachmentRef.attachment = 0;
colorAttachmentRef.layout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL;Le paramètre attachment spécifie l’attache à référencer à l'aide d'un indice correspondant à sa position dans le tableau de descriptions des attaches. Notre tableau ne consistera qu'en une seule référence de type VkAttachmentDescription, donc son indice est 0. La propriété layout indique l’agencement que doit avoir l’attache pendant l’exécution de la sous-passe l’utilisant. Vulkan changera automatiquement l'agencement de l’attache au début de la sous-passe. Nous souhaitons que l’attache soit un tampon de couleur avec l’agencement VK_IMAGE_LAYOUT_COLOR_OPTIMAL. Comme son nom le suggère, cela nous donnera de meilleures performances.
La sous-passe est décrite dans la structure VkSubpassDescription :
VkSubpassDescription subpass{};
subpass.pipelineBindPoint = VK_PIPELINE_BIND_POINT_GRAPHICS;Dans le futur, Vulkan pourra supporter des sous-passes de calcul. Par conséquent, nous devons indiquer que notre sous-passe est une sous-passe graphique. Ensuite, nous spécifions la référence à l’attache de couleur :
subpass.colorAttachmentCount = 1;
subpass.pColorAttachments = &colorAttachmentRef;L'indice de cette attache est directement mentionné dans le fragment shader avec la directive layout(location = 0) out vec4 outColor.
Les types d’attaches suivants peuvent être référencés dans une sous passe :
- pInputAttachments : attaches lues depuis un shader ;
- pResolveAttachments : attaches utilisées pour le multiéchantillonnage des attaches de couleur ;
- pDepthStencilAttachment : attaches pour la profondeur et le pochoir ;
- pPreserveAttachments : attaches qui ne sont pas utilisées par cette sous-passe, mais dont les données doivent être conservées.
IV-C-4-d. Passe de rendu▲
Maintenant que l’attache et qu’une sous-passe la référençant ont été mises en place, nous pouvons créer la passe de rendu. Créez une nouvelle variable du type VkRenderPass au-dessus de la variable pipelineLayout :
VkRenderPass renderPass;
VkPipelineLayout pipelineLayout;L'objet représentant la passe de rendu peut être créé en remplissant la structure VkRenderPassCreateInfo avec un tableau d’attaches et un tableau de sous passes. Les objets VkAttachmentReference référencent les attaches en utilisant les indices de ce tableau.
VkRenderPassCreateInfo renderPassInfo{};
renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_CREATE_INFO;
renderPassInfo.attachmentCount = 1;
renderPassInfo.pAttachments = &colorAttachment;
renderPassInfo.subpassCount = 1;
renderPassInfo.pSubpasses = &subpass;
if (vkCreateRenderPass(device, &renderPassInfo, nullptr, &renderPass) != VK_SUCCESS) {
throw std::runtime_error("Échec lors de la création de la passe de rendu !");
}Comme pour l'agencement du pipeline, nous aurons à utiliser la passe de rendu tout au long du programme. Nous devons donc la détruire dans la fonction cleanup() :
void cleanup() {
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
vkDestroyRenderPass(device, renderPass, nullptr);
...
}Nous avons eu beaucoup de travail. Dans le prochain chapitre, nous allons assembler le tout et créer le pipeline graphique !
IV-C-5. Conclusion▲
Nous pouvons maintenant combiner toutes les structures et tous les objets des chapitres précédents pour créer le pipeline graphique ! Voici un petit récapitulatif des objets que nous avons :
- étapes programmables : les modules de shader qui définissent le fonctionnement des étapes programmables du pipeline graphique ;
- étapes fixes : plusieurs structures qui paramètrent les étapes fixes comme l'assemblage des entrées, le rastériseur, le viewport et le mélange des couleurs ;
- l’agencement du pipeline : les valeurs uniformes et les constantes poussées utilisées par les shaders et pouvant être modifiées lors du rendu ;
- la passe de rendu : les attaches référencées par le pipeline et leur utilisation.
Tous ces éléments rassemblés permettent de définir le fonctionnement du pipeline graphique. Nous pouvons donc maintenant remplir la structure VkGraphicsPipelineCreateInfo à la fin de la fonction createGraphicsPipeline(), toutefois, nous devons remplir cette structure avant l’appel à la fonction vkDestroyShaderModule(), car cette dernière détruit les shaders dont le pipeline a besoin.
VkGraphicsPipelineCreateInfo pipelineInfo{};
pipelineInfo.sType = VK_STRUCTURE_TYPE_GRAPHICS_PIPELINE_CREATE_INFO;
pipelineInfo.stageCount = 2;
pipelineInfo.pStages = shaderStages;Commençons par référencer le tableau de VkPipelineShaderStageCreateInfo.
pipelineInfo.pVertexInputState = &vertexInputInfo;
pipelineInfo.pInputAssemblyState = &inputAssembly;
pipelineInfo.pViewportState = &viewportState;
pipelineInfo.pRasterizationState = &rasterizer;
pipelineInfo.pMultisampleState = &multisampling;
pipelineInfo.pDepthStencilState = nullptr; // Optionnel
pipelineInfo.pColorBlendState = &colorBlending;
pipelineInfo.pDynamicState = nullptr; // OptionnelPuis spécifions les structures décrivant les étapes fixes.
pipelineInfo.layout = pipelineLayout;Après cela vient l’agencement du pipeline. Ici, il faut passer la structure par copie plutôt que par un pointeur.
pipelineInfo.renderPass = renderPass;
pipelineInfo.subpass = 0;Finalement, nous avons une référence à la passe de rendu, ainsi que l’indice de la sous-passe dans laquelle le pipeline sera utilisé. Il est aussi possible d’utiliser d’autres passes de rendu avec le pipeline de cette instance, mais elles doivent toutes être compatibles avec renderPass. Cette notion de compatibilité est décrite ici, mais nous n'utiliserons pas cette possibilité dans ce tutoriel.
pipelineInfo.basePipelineHandle = VK_NULL_HANDLE; // Optionnel
pipelineInfo.basePipelineIndex = -1; // OptionnelEn réalité, il nous reste deux paramètres : basePipelineHandle et basePipelineIndex. Vulkan vous permet de créer un nouveau pipeline à partir d’un pipeline existant. L'idée derrière cette fonctionnalité est qu'il est moins coûteux de créer un pipeline à partir d'un autre partageant la plupart des fonctionnalités et le changement d’un pipeline à un autre peut être réalisé plus rapidement lorsqu’ils ont le même parent. Vous pouvez spécifier un pipeline de deux manières : soit en fournissant une référence à un pipeline existant avec basePipelineHandle, soit en donnant l'indice d’un pipeline qui va être créé avec basePipelineIndex. Pour le moment, nous n’avons qu’un seul pipeline. Nous passons donc un pointeur nul et un index invalide. Ces valeurs ne sont utilisées que si le champ VK_PIPELINE_CREATE_DERIVATIVE_BIT est spécifié dans la propriété flags de la structure VkGraphicsPipelineCreateInfo.
Préparons l'étape finale en créant une variable membre où stocker l’objet de type VkPipeline :
VkPipeline graphicsPipeline;Finalement, créons le pipeline graphique :
if (vkCreateGraphicsPipelines(device, VK_NULL_HANDLE, 1, &pipelineInfo, nullptr, &graphicsPipeline) != VK_SUCCESS) {
throw std::runtime_error("Échec pour créer le pipeline graphique !");
}La fonction vkCreateGraphicsPipelines() possède plus de paramètres que les fonctions de création d'objets que nous avons pu voir jusqu'à présent. Elle peut en effet accepter plusieurs structures VkGraphicsPipelineCreateInfo et créer plusieurs VkPipeline en un seul appel.
Le second paramètre, pour lequel nous passons VK_NULL_HANDLE, référence un objet VkPipelineCache optionnel. Un cache de pipelines peut être utilisé pour stocker et réutiliser des données utiles lors des différents appels à VkCreateGraphicsPipelines() et même entre plusieurs exécutions du programme si le cache est sauvegardé dans un fichier. Cela permet de grandement accélérer la création. Nous verrons ce cas dans un chapitre dédié.
Le pipeline graphique est nécessaire lors des opérations de dessin, nous devons donc le détruire à la fin du programme :
void cleanup() {
vkDestroyPipeline(device, graphicsPipeline, nullptr);
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
...
}Exécutez votre programme pour vérifier que tout ce travail a permis la création d’un pipeline graphique sans erreur ! Nous sommes de plus en plus proches d'obtenir quelque chose à l’écran ! Dans les prochains chapitres, nous configurerons les tampons d’image à partir des images de la « swap chain » et préparerons les commandes de dessin.
IV-D. Rendu▲
IV-D-1. Tampons d’images▲
Nous avons beaucoup parlé de tampons d’images dans les chapitres précédents et nous avons mis en place une passe de rendu qui attend un tampon d’images avec le même format que les images provenant de la « swap chain ». Toutefois, nous ne l’avons toujours pas créé.
Les attaches spécifiées durant la création de la passe de rendu sont liées en les associant à un objet de type VkFramebuffer. Cet objet référence toutes les vues (VkImageView) correspondant aux attaches. Par contre, l’image que nous devons utiliser comme attache dépend de l’image retournée par la « swap chain » lorsque nous en récupérons une pour l’affichage. Cela signifie que nous devons créer un tampon d’images pour toutes les images de la « swap chain » et utiliser le tampon qui correspond à l’image reçue au moment du rendu.
Pour cela, créons un autre std::vector membre de la classe et qui contiendra les tampons d’image :
std::vector<VkFramebuffer> swapChainFramebuffers;Les objets qui rempliront ce tableau seront créés dans une nouvelle fonction nommée createFramebuffers() que nous appellerons depuis la fonction initVulkan() juste après la création du pipeline graphique :
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
}
...
void createFramebuffers() {
}Commencez par redimensionner le conteneur afin qu'il puisse stocker tous les tampons d’image :
void createFramebuffers() {
swapChainFramebuffers.resize(swapChainImageViews.size());
}Nous allons maintenant itérer sur toutes les vues d’images et créer un tampon d’images à partir de chacune d'elles :
for (size_t i = 0; i < swapChainImageViews.size(); i++) {
VkImageView attachments[] = {
swapChainImageViews[i]
};
VkFramebufferCreateInfo framebufferInfo{};
framebufferInfo.sType = VK_STRUCTURE_TYPE_FRAMEBUFFER_CREATE_INFO;
framebufferInfo.renderPass = renderPass;
framebufferInfo.attachmentCount = 1;
framebufferInfo.pAttachments = attachments;
framebufferInfo.width = swapChainExtent.width;
framebufferInfo.height = swapChainExtent.height;
framebufferInfo.layers = 1;
if (vkCreateFramebuffer(device, &framebufferInfo, nullptr, &swapChainFramebuffers[i]) != VK_SUCCESS) {
throw std::runtime_error("Échec lors de la création du tampon d’image !");
}
}Comme vous le pouvez le voir, la création d'un tampon d’images est assez simple. Nous devons d'abord indiquer avec quelle passe de rendu le tampon d’images doit être compatible. Vous ne pouvez utiliser qu’un tampon d’images qui est compatible avec la passe de rendu, c’est-à-dire que le tampon et la passe de rendu doivent globalement avoir le même nombre d’attaches et qu’elles soient du même type.
Les paramètres attachementCount et pAttachments spécifient les objets de type VkImageView qui doivent être liés aux descriptions d’attaches que nous avons spécifiées dans le tableau pAttachment de la passe de rendu.
Les paramètres width et height sont évidents. La propriété layers correspond au nombre de couches dans les tableaux d’image. Les images de notre « swap chain » sont uniques, donc nous spécifions 1.
Nous devons détruire les tampons d’images avant les vues d’images et avant la passe de rendu, mais seulement après la fin du rendu :
void cleanup() {
for (auto framebuffer : swapChainFramebuffers) {
vkDestroyFramebuffer(device, framebuffer, nullptr);
}
...
}Nous avons atteint le moment où tous les objets sont prêts pour le rendu. Dans le prochain chapitre, nous allons écrire les premières commandes de rendu.
IV-D-2. Tampons de commandes▲
Dans Vulkan, les commandes comme les opérations de dessin ou de transfert mémoire ne sont pas réalisées avec des appels de fonctions. Il faut enregistrer toutes les opérations dans des tampons de commandes. L'avantage est que vous pouvez faire ce travail en amont, et ce, depuis plusieurs threads. Ensuite, il ne reste plus qu’à dire à Vulkan d’exécuter les commandes dans la boucle principale.
IV-D-2-a. Groupe de commandes▲
Nous devons créer un groupe de commandes (command pool) avant de pouvoir créer les tampons de commandes. Les groupes gèrent la mémoire nécessaire pour stocker les tampons. Les tampons de commandes sont alloués à partir des groupes. Ajoutez un nouveau membre à la classe pour stocker une variable de type VkCommandPool :
VkCommandPool commandPool;Créez ensuite la fonction nommée createCommandPool et appelez-la depuis la fonction initVulkan() après la création des tampons d’images.
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
}
...
void createCommandPool() {La création d'un groupe de commandes ne nécessite que deux paramètres :
QueueFamilyIndices queueFamilyIndices = findQueueFamilies(physicalDevice);
VkCommandPoolCreateInfo poolInfo{};
poolInfo.sType = VK_STRUCTURE_TYPE_COMMAND_POOL_CREATE_INFO;
poolInfo.queueFamilyIndex = queueFamilyIndices.graphicsFamily.value();
poolInfo.flags = 0; // OptionnelLes tampons de commandes sont exécutés en les envoyant à une queue, telle que celles que nous avons récupérées pour les graphiques et l’affichage. Chaque groupe de commandes ne peut allouer que des tampons de commandes qui seront envoyés à un type unique de queue. Nous allons enregistrer des commandes pour le dessin, c’est pourquoi nous avons choisi la famille de queue pour les graphiques.
Il existe deux valeurs acceptées par la propriété flags des groupes de commandes :
- VK_COMMAND_POOL_CREATE_TRANSIENT_BIT : informe que les tampons de commandes sont très souvent réenregistrés avec de nouvelles commandes (le comportement de l’allocation de la mémoire peut être différent) ;
- VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT : permet aux tampons de commandes d'être réenregistrés individuellement. Sans cet indicateur, ils doivent tous être réinitialisés ensemble.
Nous n'enregistrerons les tampons de commandes qu'une seule fois, au début du programme, et les exécuterons énormément de fois dans la boucle principale. Nous n’avons donc pas besoin de ces indications.
if (vkCreateCommandPool(device, &poolInfo, nullptr, &commandPool) != VK_SUCCESS) {
throw std::runtime_error("Échec de création du groupe de commandes !");
}La création du groupe de commandes s’effectue avec la fonction vkCreateComandPool(). Elle ne possède aucun paramètre particulier. Les commandes seront utilisées tout au long du programme pour dessiner des choses à l’écran. Donc, le groupe ne doit être détruit qu’à la fin, dans la fonction cleanup() :
void cleanup() {
vkDestroyCommandPool(device, commandPool, nullptr);
...
}IV-D-2-b. Allocation des tampons de commandes▲
Nous pouvons maintenant allouer des tampons de commandes et y enregistrer des commandes de rendu. Dans la mesure où l'une des commandes consiste à lier le bon tampon d’image (VkFramebuffer), nous devons enregistrer un tampon pour chaque image de la « swap chain ». Pour cela, créez une liste d’objets de type VkCommandBuffer et stockez-la dans une variable membre de la classe. Les tampons de commande sont libérés automatiquement lorsque leur groupe de commandes est détruit. Nous n’avons donc pas besoin de le faire explicitement.
std::vector<VkCommandBuffer> commandBuffers;Commençons maintenant à travailler sur une nouvelle fonction createCommandBuffers() qui allouera et enregistrera les tampons de commandes pour chacune des images de la « swap chain ».
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
createCommandBuffers();
}
...
void createCommandBuffers() {
commandBuffers.resize(swapChainFramebuffers.size());
}Les tampons de commandes sont alloués en appelant la fonction vkAllocateCommandBuffers() qui prend en paramètre une structure du type VkCommandBufferAllocateInfo. Cette structure spécifie le groupe de commandes et le nombre de tampons à allouer :
VkCommandBufferAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO;
allocInfo.commandPool = commandPool;
allocInfo.level = VK_COMMAND_BUFFER_LEVEL_PRIMARY;
allocInfo.commandBufferCount = (uint32_t) commandBuffers.size();
if (vkAllocateCommandBuffers(device, &allocInfo, commandBuffers.data()) != VK_SUCCESS) {
throw std::runtime_error("Échec d’allocation des tampons de commandes !");
}Le paramètre level indique si les tampons de commandes alloués sont primaires ou secondaires :
- VK_COMMAND_BUFFER_LEVEL_PRIMARY : peut être envoyé à une queue pour y être exécuté, mais ne peut pas être appelé à partir d'autres tampons de commandes ;
- VK_COMMAND_BUFFER_LEVEL_SECONDARY : ne peut pas être directement envoyé à une queue, mais peut être appelé à partir d’un tampon de commandes primaire.
Nous n'utiliserons pas de tampon de commandes secondaire, mais vous pouvez voir que ce mécanisme est utile pour réutiliser des opérations communes dans des tampons de commandes primaires.
IV-D-2-c. Commencer l'enregistrement des commandes▲
Nous commençons l'enregistrement des commandes dans le tampon de commandes en appelant la fonction vkBeginCommandBuffer(). Cette fonction prend en paramètre une structure du type VkCommandBufferBeginInfo. Elle spécifie quelques détails sur l'utilisation du tampon de commandes.
for (size_t i = 0; i < commandBuffers.size(); i++) {
VkCommandBufferBeginInfo beginInfo{};
beginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
beginInfo.flags = 0; // Optionnel
beginInfo.pInheritanceInfo = nullptr; // Optionnel
if (vkBeginCommandBuffer(commandBuffers[i], &beginInfo) != VK_SUCCESS) {
throw std::runtime_error("Échec de lancement de l’enregistrement du tampon de commandes !");
}
}Le paramètre flags indique notre utilisation du tampon de commandes. Voici une liste des valeurs disponibles :
- VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT : le tampon de commandes sera réenregistré juste après son utilisation ;
- VK_COMMAND_BUFFER_USAGE_RENDER_PASS_CONTINUE_BIT : le tampon de commandes secondaire sera intégralement exécuté dans une unique passe de rendu ;
- VK_COMMAND_BUFFER_USAGE_SIMULTANEOUS_USE_BIT : le tampon de commandes peut être réenvoyé alors qu'il est déjà en cours d'exécution.
Nous n'avons besoin d’aucune de ces valeurs ici.
Le paramètre pInheritanceInfo n'a de sens que pour les tampons de commandes secondaires. Il indique de quel état hériter lors de l'appel par un tampon de commandes primaire.
Si un tampon de commandes a déjà été enregistré, alors un appel à la fonction vkBeginCommandBuffer() le réinitialisera. Il n'est pas possible d’ajouter des commandes à un tampon une fois son enregistrement fini.
IV-D-2-d. Commencer une passe de rendu▲
Le rendu démarre par le lancement de la passe de rendu grâce à la fonction vkCmdBeginRenderPass(). La passe est configurée grâce aux paramètres de la structure de type VkRenderPassBeginInfo.
VkRenderPassBeginInfo renderPassInfo{};
renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_BEGIN_INFO;
renderPassInfo.renderPass = renderPass;
renderPassInfo.framebuffer = swapChainFramebuffers[i];Les premiers paramètres indiquent la passe de rendu et les attaches à lier. Nous avons créé un tampon d’images pour chaque image de la « swap chain » spécifiant l’attache pour les couleurs.
renderPassInfo.renderArea.offset = {0, 0};
renderPassInfo.renderArea.extent = swapChainExtent;Les deux paramètres qui suivent définissent la taille de la zone de rendu. Cette zone de rendu définit où les shaders vont charger et écrire. Les pixels hors de cette région auront une valeur non définie. Cette zone doit correspondre à la taille des attaches pour obtenir les meilleures performances.
VkClearValue clearColor = {0.0f, 0.0f, 0.0f, 1.0f};
renderPassInfo.clearValueCount = 1;
renderPassInfo.pClearValues = &clearColor;Les deux derniers paramètres définissent les valeurs à utiliser pour réinitialiser le tampon lors de l’opération VK_ATTACHMENT_LOAD_CLEAR que nous avons mise en place lors du chargement de l’attache des couleurs. J'ai utilisé un noir complètement opaque.
vkCmdBeginRenderPass(commandBuffers[i], &renderPassInfo, VK_SUBPASS_CONTENTS_INLINE);La passe de rendu peut maintenant commencer. Toutes les fonctions enregistrant des commandes ont le préfixe vkCmd. Comme elles retournent toutes void, nous n'avons aucun moyen de détecter une erreur tant que l’enregistrement n’est pas fini.
Le premier paramètre de chaque commande est toujours le tampon de commandes qui stockera l'appel. Le second paramètre donne des détails sur la passe de rendu que nous venons de fournir. Le dernier paramètre contrôle comment les commandes de rendu comprises dans la passe de rendu seront fournies. Nous avons deux possibilités :
- VK_SUBPASS_CONTENTS_INLINE : les commandes de la passe de rendu seront directement embarquées dans le tampon de commandes et aucun tampon secondaire ne sera exécuté ;
- VK_SUBPASS_CONTENTS_SECONDARY_COMMAND_BUFFER : les commandes de la passe de rendu seront exécutées à partir de tampons de commandes secondaires.
Nous n'utiliserons pas de tampon de commandes secondaire, nous devons donc fournir la première valeur.
IV-D-2-e. Commandes de rendu basiques▲
Nous pouvons maintenant lier le pipeline graphique :
vkCmdBindPipeline(commandBuffers[i], VK_PIPELINE_BIND_POINT_GRAPHICS, graphicsPipeline);Le deuxième paramètre indique si le pipeline passé est un pipeline graphique ou de calcul. Nous avons maintenant fourni quelles opérations à exécuter dans le pipeline graphique et quelle attache utiliser dans le fragment shader. Il ne reste plus qu’à indiquer de dessiner le triangle :
vkCmdDraw(commandBuffers[i], 3, 1, 0, 0);La fonction vkCmdDraw() est assez ridicule quand on sait tout ce que nous avons fait pour en arriver là. En plus du tampon de commandes, elle possède les paramètres suivants :
- vertexCount : même si nous n'avons pas de tampon de sommets, nous avons techniquement trois sommets à dessiner ;
- instanceCount : utilisé lors d’un rendu avec instanciation. Indiquez 1 si vous ne l'utilisez pas ;
- firstVertex : utilisé comme décalage dans le tampon de sommets et définit ainsi la valeur la plus basse pour glVertexIndex ;
- firstInstance : utilisé comme décalage pour l’instanciation et définit ainsi la valeur la plus basse pour gl_InstanceIndex.
IV-D-2-f. Finalisation▲
La passe de rendu peut ensuite être terminée :
vkCmdEndRenderPass(commandBuffers[i]);Et nous avons fini l'enregistrement du tampon de commandes :
if (vkEndCommandBuffer(commandBuffers[i]) != VK_SUCCESS) {
throw std::runtime_error("Erreur d’enregistrement du tampon de commandes !");
}Dans le prochain chapitre, nous écrirons le code pour la boucle principale. Elle récupérera une image provenant de la « swap chain », exécutera le bon tampon de commandes et renverra l'image complète à la « swap chain ».
IV-D-3. Rendu et présentation▲
IV-D-3-a. Mise en place▲
Nous en sommes au chapitre où tout s'assemble. Nous allons écrire une fonction drawFrame() qui sera appelée depuis la boucle principale et affichera les triangles à l'écran. Créez la fonction et appelez-la depuis la fonction mainLoop() :
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
}
...
void drawFrame() {
}IV-D-3-b. Synchronisation▲
La fonction drawFrame() réalisera les opérations suivantes :
- récupérer une image depuis la « swap chain » ;
- exécuter le tampon de commandes avec l’image obtenue comme attache du tampon d’images ;
- retourner l'image à la « swap chain » pour l’afficher.
Chacune de ces actions n'est réalisée qu'avec un appel de fonction. Cependant, elles sont asynchrones. Les appels de fonction finiront avant que les opérations ne soient réellement terminées. De plus, l’ordre d’exécution des opérations n’est pas déterministe. C’est dommage, d’autant plus que chacune de ces opérations dépend de la précédente.
Il y a deux manières d’ordonnancer les événements de la « swap chain » : utiliser les barrières (fences) et les sémaphores. Ces deux types d’objets peuvent être utilisés pour coordonner les opérations. En effet, chaque opération sera en attente du déclenchement de la barrière ou du sémaphore. Le déclenchement se produira après la fin de l’opération précédente.
Toutefois, il existe une différence entre les barrières et les sémaphores : les barrières sont les seules dont l’état peut être récupéré par le programme grâce à la fonction vkWaitForFences(). Les barrières sont principalement utilisées pour ordonnancer les actions de l’application elle-même entre les opérations de rendu alors que les sémaphores sont utilisés pour ordonnancer les opérations à l’intérieur ou entre les queues de commandes. Nous souhaitons agencer les opérations de rendu d’une queue et de l’affichage, nous utiliserons donc des sémaphores qui correspondent mieux à ce besoin.
IV-D-3-c. Sémaphores▲
Nous avons besoin d'un sémaphore pour indiquer qu’une image est prête pour le rendu et d’un deuxième sémaphore pour signaler que le rendu est terminé et que l’affichage peut avoir lieu. Créez donc deux membres de la classe pour stocker ces objets :
VkSemaphore imageAvailableSemaphore;
VkSemaphore renderFinishedSemaphore;Pour créer les sémaphores, nous allons ajouter une dernière fonction nommée createSemaphores() dans la fonction initVulkan() :
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
createCommandBuffers();
createSemaphores();
}
...
void createSemaphores() {
}La création d'un sémaphore nécessite de renseigner la structure VkSemaphoreCreateInfo. Toutefois, dans la version actuelle de la bibliothèque, la structure ne contient que la propriété sType :
void createSemaphores() {
VkSemaphoreCreateInfo semaphoreInfo{};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
}Les prochaines versions de Vulkan (ou des extensions) pourraient ajouter des fonctionnalités au travers des paramètres flags et pNext, comme c’est le cas avec d’autres structures. La création d’un sémaphore suit le processus habituel :
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphore) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphore) != VK_SUCCESS) {
throw std::runtime_error("Échec de création des sémaphores !");
}Les sémaphores doivent être détruits à la fin du programme, lorsque toutes les commandes sont terminées et qu’il n’y a donc plus besoin de mécanisme de synchronisation :
void cleanup() {
vkDestroySemaphore(device, renderFinishedSemaphore, nullptr);
vkDestroySemaphore(device, imageAvailableSemaphore, nullptr);IV-D-3-d. Obtention d’une image provenant de la « swap chain »▲
Comme indiqué ci-dessus, la première chose à faire dans la fonction drawFrame() est d’obtenir une image provenant de la « swap chain ». Comme la « swap chain » est une fonctionnalité provenant d’une extension, nous devons utiliser une fonction nommée vk*KHR :
void drawFrame() {
uint32_t imageIndex;
vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphore, VK_NULL_HANDLE, &imageIndex);
}Les deux premiers paramètres de la fonction vkAcquireNextImageKHR() sont le périphérique logique et la « swap chain » depuis laquelle récupérer une image. Le troisième paramètre spécifie une durée maximale en nanosecondes avant d'abandonner l'attente si aucune image n'est disponible. Vous pouvez désactiver cette expiration en utilisant la plus grande valeur pour un entier non signé sur 64 bits.
Les deux paramètres suivants indiquent les objets de synchronisation qui doivent être utilisés pour signaler lorsque le moteur d’affichage a terminé d’utiliser l’image. C’est à ce moment-là que nous pouvons dessiner dedans. Il est possible de donner en paramètre un sémaphore, une barrière ou les deux. Nous allons utiliser notre sémaphore imageAvailableSemaphore pour cela.
Le dernier paramètre permet de récupérer une variable dans laquelle est placé l’indice de l’image de la « swap chain » qui vient d’être mise à disposition. L’indice correspond à un objet de type VkImage présent dans notre tableau swapChainImages. Nous allons aussi utiliser cet indice pour choisir le bon tampon de commandes.
IV-D-3-e. Envoi du tampon de commandes▲
L'envoi de la queue et la synchronisation se configurent au travers des paramètres de la structure VkSubmitInfo.
VkSubmitInfo submitInfo{};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
VkSemaphore waitSemaphores[] = {imageAvailableSemaphore};
VkPipelineStageFlags waitStages[] = {VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT};
submitInfo.waitSemaphoreCount = 1;
submitInfo.pWaitSemaphores = waitSemaphores;
submitInfo.pWaitDstStageMask = waitStages;Les trois premiers paramètres indiquent le sémaphore à attendre avant de commencer l’exécution et à quelle étape du pipeline attendre. Nous souhaitons attendre que l’image soit disponible avant d’écrire les couleurs dans l’image. En théorie, cela signifie que l’implémentation peut déjà exécuter notre vertex shader et d’autres étapes même si l’image n’est pas encore disponible. Chaque entrée dans le tableau waitStages correspond au sémaphore dans pWaitSemaphores de même indice.
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &commandBuffers[imageIndex];Les deux paramètres qui suivent indiquent les tampons de commandes à exécuter. Nous devons ici fournir le tampon de commandes qui utilise l'image de la « swap chain » que nous venons de récupérer comme attache de couleurs.
VkSemaphore signalSemaphores[] = {renderFinishedSemaphore};
submitInfo.signalSemaphoreCount = 1;
submitInfo.pSignalSemaphores = signalSemaphores;Les paramètres signalSemaphoreCount et pSignalSemaphores indiquent quels sémaphores déclencher lorsque l’exécution du tampon de commandes est terminée. Dans notre cas, nous utilisons le sémaphore renderFinishedSemaphore.
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, VK_NULL_HANDLE) != VK_SUCCESS) {
throw std::runtime_error("Échec d’envoi du tampon de commandes pour le rendu !");
}Nous pouvons maintenant envoyer notre tampon de commandes à la queue graphique grâce à la fonction vkQueueSubmit(). Cette fonction prend en argument un tableau de structures de type VkSubmitInfo pour une question d'efficacité. Le dernier paramètre permet de fournir une barrière optionnelle déclenchée lorsque le tampon de commandes s’est exécuté. N’en ayant pas l’usage, nous passons VK_NULL_HANDLE.
IV-D-3-f. Dépendances des sous-passes▲
Les sous-passes de la passe de rendu gèrent automatiquement les transitions de l’agencement de l’image. Ces transitions sont contrôlées par les dépendances de sous-passes. Elles permettent de décrire les dépendances liées à la mémoire ou à l’exécution des sous-passes. Nous n’avons qu’une seule sous-passe pour le moment, mais les opérations juste avant et après cette sous-passe comptent comme sous-passes implicites.
Il existe deux dépendances embarquées dans Vulkan capables de gérer les transitions au début et à la fin de la passe de rendu. Toutefois, cette première dépendance ne s'exécute pas au bon moment. Elle part du principe que la transition démarre au début du pipeline, mais nous n’avons pas encore l’image à ce moment-là ! Il existe deux méthodes pour gérer ce cas. Nous pouvons modifier waitStages pour imageAvailableSemaphore à VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT pour être sûrs que la passe de rendu ne commence pas tant que l’image n’est pas disponible. Sinon, nous pouvons faire en sorte que la passe de rendu attende l’étape VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT. J’ai décidé d’implémenter cette deuxième option, car c’est une bonne occasion de détailler les dépendances de sous-passe et leur fonctionnement.
Les dépendances de sous-passe sont spécifiées à l’aide d’une structure du type VkSubpassDependency. Allez à la fonction createRenderPass() pour en ajouter une :
VkSubpassDependency dependency{};
dependency.srcSubpass = VK_SUBPASS_EXTERNAL;
dependency.dstSubpass = 0;Les deux premiers champs permettent de fournir l'indice de la dépendance et la sous-passe de laquelle dépendre. La valeur VK_SUBPASS_EXTERNAL réfère à la sous-passe implicite avant ou après la passe de rendu selon que vous utilisez srcSubpass ou dstSubpass. L'indice 0 correspond à notre seule et unique sous-passe. La valeur fournie à dstSubpass doit toujours être supérieure à srcSubpass pour éviter les boucles infinies (sauf si une des sous-passes est VK_SUBPASS_EXTERNAL).
dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.srcAccessMask = 0;Les deux paramètres suivants indiquent les opérations à attendre et les étapes durant lesquelles les opérations à attendre se produisent. Nous voulons attendre que la « swap chain » finisse de lire l’image avant d’y accéder. Nous pouvons attendre que l’étape d’écriture de l’attache de couleurs se termine. Cela revient au même.
dependency.dstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.dstAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT;Nous indiquons ici que les opérations qui doivent attendre pendant l'étape liée à l’attache de couleurs sont celles ayant trait à l’écriture de l’attache de couleurs. Ces paramètres permettent d’effectuer la transition uniquement lorsque nécessaire (et permis) : lorsque nous souhaitons écrire les couleurs.
renderPassInfo.dependencyCount = 1;
renderPassInfo.pDependencies = &dependency;La structure VkRenderPassCreateInfo possède deux champs pour spécifier un tableau de dépendances.
IV-D-3-g. Affichage▲
La dernière étape consiste à envoyer le résultat à la « swap chain » afin que celle-ci l’affiche à l’écran. L’affichage se configure grâce à une structure de type VkPresentInfoKHR, que nous gérons à la fin de la fonction drawFrame().
VkPresentInfoKHR presentInfo{};
presentInfo.sType = VK_STRUCTURE_TYPE_PRESENT_INFO_KHR;
presentInfo.waitSemaphoreCount = 1;
presentInfo.pWaitSemaphores = signalSemaphores;Les deux premiers paramètres permettent d'indiquer quels sémaphores attendre avant que l’affichage ne puisse être effectué.
VkSwapchainKHR swapChains[] = {swapChain};
presentInfo.swapchainCount = 1;
presentInfo.pSwapchains = swapChains;
presentInfo.pImageIndices = &imageIndex;Les deux paramètres suivants spécifient un tableau de « swap chains » auxquelles envoyer les images et l’indice de l’image dans chaque « swap chain ». Il n’y en aura presque toujours qu’une.
presentInfo.pResults = nullptr; // OptionnelCe dernier paramètre, nommé pResults, est optionnel. Il vous permet de fournir un tableau de VkResult que vous pourrez consulter pour vérifier que toutes les « swap chain » ont bien affiché leur image sans encombre. Cela n'est pas nécessaire dans le cas où vous n’utilisez qu’une « swap chain », car vous pouvez utiliser la valeur de retour de la fonction de présentation.
vkQueuePresentKHR(presentQueue, &presentInfo);La fonction vkQueuePresentKHR() envoie une requête de présentation d'une image à la « swap chain ». Nous ajouterons la gestion des erreurs pour vkAcquireNextImageKHR() et vkQueuePresentKHR() dans le prochain chapitre, car une erreur à ces étapes n'implique pas forcément que le programme doit se terminer, contrairement aux fonctions vues jusqu’à présent.
Si vous avez fait tout ça correctement, vous devriez avoir quelque chose comme cela à l'écran quand vous lancez votre programme :
![[ALT-PASTOUCHE]](./images/triangle.png)
Enfin ! Malheureusement, si vous avez les couches de validation actives, vous verrez que le programme « crashe » dès que vous essayez de le fermer. Les messages qui s’affichent dans le terminal nous en indiquent la raison :
![[ALT-PASTOUCHE]](./images/semaphore_in_use.png)
N'oubliez pas que les opérations dans la fonction drawFrame() sont asynchrones. Il est donc probable que, lorsque vous quittez la boucle dans mainLoop(), celle-ci effectue toujours des opérations de rendu ou d’affichage. Libérer des ressources dans de telles conditions n’est pas une bonne idée.
Pour régler ce problème, nous devons attendre que le périphérique logique termine ses opérations avant de quitter la fonction mainLoop() :
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
vkDeviceWaitIdle(device);
}Vous pouvez également attendre la fin des opérations d’une queue de commandes grâce à la fonction vkQueueWaitIdle(). Cette fonction peut aussi être utilisée pour mettre en place une synchronisation rudimentaire. Le programme devrait maintenant se terminer sans problème quand vous fermez la fenêtre.
IV-D-3-h. Rendu en cours▲
Si vous lancez l'application avec les couches de validations activées, vous aurez peut-être des erreurs ou une consommation mémoire qui augmente au fil du temps. La raison est que l'application soumet rapidement du travail dans la fonction drawframe(), mais ne vérifie pas si ces opérations se sont effectivement terminées. Si le CPU envoie plus de commandes que le GPU ne peut en exécuter, alors la queue se remplira avec du travail. Pire encore, nous réutilisons les sémaphores imageAvailableSemaphore et renderFinishedSemaphore ainsi que le tampon de commandes pour plusieurs rendus à la fois.
Pour corriger cela, le plus simple est d'attendre que le travail soit terminé avant d’en envoyer de nouveau. C’est possible avec la fonction vkQueueWaitIdle() :
void drawFrame() {
...
vkQueuePresentKHR(presentQueue, &presentInfo);
vkQueueWaitIdle(presentQueue);
}Cependant, avec cette méthode, nous ne profitons pas de toute la puissance du GPU : le pipeline graphique n’est utilisé que pour un rendu à la fois. Les étapes ayant déjà été effectuées pour le rendu en cours peuvent déjà être réutilisées pour le prochain rendu. Nous allons modifier notre application pour permettre d’obtenir plusieurs rendus en parallèle tout en limitant l’effet d’entassement dans la queue.
Commencez par ajouter une constante en haut du programme qui définit le nombre de rendus pouvant être réalisés en parallèle :
const int MAX_FRAMES_IN_FLIGHT = 2;Chaque rendu aura ses sémaphores dédiés :
std::vector<VkSemaphore> imageAvailableSemaphores;
std::vector<VkSemaphore> renderFinishedSemaphores;La fonction createSemaphores() doit être améliorée pour gérer la création des nouveaux sémaphores :
void createSemaphores() {
imageAvailableSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
renderFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
VkSemaphoreCreateInfo semaphoreInfo{};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphores[i]) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphores[i]) != VK_SUCCESS) {
throw std::runtime_error("Échec de la création des sémaphores !");
}
}Évidemment, nous devons les libérer dans la fonction cleanup() :
void cleanup() {
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vkDestroySemaphore(device, renderFinishedSemaphores[i], nullptr);
vkDestroySemaphore(device, imageAvailableSemaphores[i], nullptr);
}
...
}Pour utiliser la bonne paire de sémaphores à chaque fois, nous devons mémoriser le rendu qui est en cours de traitement :
size_t currentFrame = 0;La fonction drawFrame() peut maintenant être modifiée pour utiliser les objets adéquats :
void drawFrame() {
vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);
...
VkSemaphore waitSemaphores[] = {imageAvailableSemaphores[currentFrame]};
...
VkSemaphore signalSemaphores[] = {renderFinishedSemaphores[currentFrame]};
...
}Nous ne devons pas oublier de faire avancer l’indice du rendu :
void drawFrame() {
...
currentFrame = (currentFrame + 1) % MAX_FRAMES_IN_FLIGHT;
}En utilisant l'opérateur de modulo %, nous pouvons nous assurer que l'indice boucle à chaque fois que nous avons traité MAX_FRAMES_IN_FLIGHT rendus.
Bien que nous ayons mis en place les objets facilitant le traitement de plusieurs images en parallèle, nous n’empêchons pas de réaliser plus de MAX_FRAMES_IN_FLIGHT rendus à la fois. Pour le moment, nous n’avons qu’un mécanisme de synchronisation GPU-GPU, mais aucun mécanisme pour synchroniser le CPU avec le GPU et ainsi connaître l’avancement du travail. Nous pouvons toujours utiliser les objets du rendu 0 alors que celui-ci est en cours de traitement.
Pour mettre en place une synchronisation CPU-GPU, Vulkan offre un autre type de primitive de synchronisation : les barrières (fences). Les barrières sont similaires aux sémaphores dans l’aspect où ceux-ci peuvent être déclenchés et attendre un tel déclenchement. Toutefois, dans ce cas, c’est notre code qui doit attendre. Nous allons d’abord créer une barrière pour chaque rendu :
std::vector<VkSemaphore> imageAvailableSemaphores;
std::vector<VkSemaphore> renderFinishedSemaphores;
std::vector<VkFence> inFlightFences;
size_t currentFrame = 0;J'ai choisi de créer les barrières avec les sémaphores dans la fonction createSemaphores() et donc de la renommer en createSyncObjects() :
void createSyncObjects() {
imageAvailableSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
renderFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
inFlightFences.resize(MAX_FRAMES_IN_FLIGHT);
VkSemaphoreCreateInfo semaphoreInfo{};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
VkFenceCreateInfo fenceInfo{};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphores[i]) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphores[i]) != VK_SUCCESS ||
vkCreateFence(device, &fenceInfo, nullptr, &inFlightFences[i]) != VK_SUCCESS) {
throw std::runtime_error("Échec de création des objets de synchronisation !");
}
}
}La création d'un objet de type VkFence est très similaire à la création d'un sémaphore. N'oubliez pas de libérer les barrières :
void cleanup() {
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vkDestroySemaphore(device, renderFinishedSemaphores[i], nullptr);
vkDestroySemaphore(device, imageAvailableSemaphores[i], nullptr);
vkDestroyFence(device, inFlightFences[i], nullptr);
}
...
}Nous allons maintenant modifier la fonction drawFrame() pour utiliser les barrières. L'appel à la fonction vkQueueSubmit() inclut un paramètre optionnel qui permet de passer la barrière à déclencher lorsque le tampon de commandes a été exécuté. Nous pouvons utiliser ce signal pour déterminer qu’un rendu est terminé.
void drawFrame() {
...
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFences[currentFrame]) != VK_SUCCESS) {
throw std::runtime_error("Échec d’envoi du tampon de commandes !");
}
...
}La dernière chose qui nous reste à modifier se trouve au début de la fonction drawFrame() afin d’attendre que le rendu soit terminé :
void drawFrame() {
vkWaitForFences(device, 1, &inFlightFences[currentFrame], VK_TRUE, UINT64_MAX);
vkResetFences(device, 1, &inFlightFences[currentFrame]);
...
}La fonction vkWaitForFences() prend en argument un tableau de barrières et attend le déclenchement d’une ou de toutes les barrières avant de rendre la main. Le paramètre VK_TRUE permet d’indiquer que nous devons attendre toutes les barrières, mais dans le cas où il n’y en a qu’une, cela importe peu. Tout comme avec la fonction vkAcquireNextImageKHR(), cette fonction prend aussi un temps avant expiration. Contrairement aux sémaphores, nous devons manuellement remettre la barrière à un état non déclenché. Cette réinitialisation se fait avec la fonction vkResetFences().
Si vous lancez le programme maintenant vous allez constater un comportement étrange. L’application ne semble plus rien afficher. En activant les couches de validation, vous aurez le message suivant :
![[ALT-PASTOUCHE]](./images/unsubmitted_fence.png)
Cela signifie que nous attendons pour une barrière qui n’a pas été envoyée à Vulkan. Le problème est que, par défaut, les barrières sont créées dans un état non déclenché. Cela signifie que la fonction vkWaitForFences() attendra pour toujours si nous n’avons pas envoyé la barrière à Vulkan auparavant. Pour corriger cela, nous allons changer la création de la barrière afin de l’initialiser avec un état déclenché comme si nous avions effectué un premier rendu qui se serait terminé :
void createSyncObjects() {
...
VkFenceCreateInfo fenceInfo{};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
fenceInfo.flags = VK_FENCE_CREATE_SIGNALED_BIT;
...
}La fuite de mémoire n’existe plus, mais le programme ne fonctionne toujours pas correctement. Si le nombre MAX_FRAMES_IN_FLIGHT est plus grand que le nombre d'images de la « swap chain » ou que la fonction vkAcquireNextImageKHR() ne retourne pas les images dans l’ordre, il devient possible que nous affichions une image déjà en cours de traitement. Pour l’éviter, nous devons enregistrer quelles sont les images en cours de traitement. Cette correspondance permettra de lier les images en cours d’utilisation à leur barrière. Ainsi nous aurons un objet pour effectuer une attente afin d’empêcher qu’un nouveau rendu utilise une image en cours de traitement.
Tout d'abord, ajoutez une nouvelle liste nommée imagesInFlight pour garder trace des images en cours d’utilisation :
std::vector<VkFence> inFlightFences;
std::vector<VkFence> imagesInFlight;
size_t currentFrame = 0;Initialisez la liste dans la fonction createSyncObjects() :
void createSyncObjects() {
imageAvailableSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
renderFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
inFlightFences.resize(MAX_FRAMES_IN_FLIGHT);
imagesInFlight.resize(swapChainImages.size(), VK_NULL_HANDLE);
...
}Initialement, aucun rendu n'utilise d'image, donc on peut explicitement initialiser la liste à une valeur indiquant l’absence de barrière. Maintenant, nous allons modifier la fonction drawFrame() pour attendre la fin de n’importe quel rendu qui serait en train d'utiliser l'image que nous avons reçue pour le prochain rendu.
void drawFrame() {
...
vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);
// Vérifie si le rendu précédent utilise cette image (c’est-à-dire il y a une barrière à attendre)
if (imagesInFlight[imageIndex] != VK_NULL_HANDLE) {
vkWaitForFences(device, 1, &imagesInFlight[imageIndex], VK_TRUE, UINT64_MAX);
}
// Marque l’image comme étant maintenant utilisée par ce rendu
imagesInFlight[imageIndex] = inFlightFences[currentFrame];
...
}Parce que nous avons maintenant plus d'appels à la fonction vkWaitForFences(), les appels à la fonction vkResetFences() doivent être déplacés. Le mieux reste de simplement l'appeler juste avant d'utiliser la barrière :
void drawFrame() {
...
vkResetFences(device, 1, &inFlightFences[currentFrame]);
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFences[currentFrame]) != VK_SUCCESS) {
throw std::runtime_error("Échec d’envoi du tampon de commandes du rendu !");
}
...
}Nous avons implémenté toutes les synchronisations nécessaires pour garantir qu’il y a un maximum de deux rendus en cours de traitement et que ces rendus n’utilisent pas la même image. Notez qu’il est correct pour les autres morceaux de code, tels que le nettoyage final, de reposer sur une synchronisation plus basique comme vkDeviceWaitIdle(). L’approche à adopter dépend de votre besoin de performances.
Pour en apprendre plus sur la synchronisation, rendez-vous sur cet article de Khronos.
IV-D-3-i. Conclusion▲
Un peu plus de 900 lignes plus tard nous avons enfin atteint le moment où nous avons des résultats à l'écran ! Le démarrage avec Vulkan demande vraiment beaucoup de travail, mais ce qu’il faut retenir c’est que Vulkan vous donne énormément de contrôle à travers sa verbosité. Je vous recommande de prendre un peu de temps pour relire le code et vous construire une vue d’esprit du but de chaque objet Vulkan et comment ils interagissent. Nous allons reposer sur cette connaissance pour étendre les fonctionnalités du programme.
Dans le prochain chapitre, nous allons voir une autre petite chose nécessaire à tout bon programme Vulkan.
IV-E. Recréation de la « swap chain »▲
IV-E-1. Introduction▲
Notre application affiche enfin un triangle, mais certains cas ne sont pas gérés correctement. Il est possible que la surface associée à la fenêtre soit modifiée d’une certaine façon, rendant la « swap chain » incompatible.Ce cas survient notamment lorsqu’on redimensionne la fenêtre. Nous allons donc mettre en place un code s’exécutant lors d’un redimensionnement.
IV-E-2. Recréer la « swap chain »▲
Créez la fonction recreateSwapChain() qui appelle la fonction createSwapChain() et toutes les fonctions créant un objet dépendant de la « swap chain » ou de la taille de la fenêtre.
void recreateSwapChain() {
vkDeviceWaitIdle(device);
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandBuffers();
}Nous appelons d'abord la fonction vkDeviceWaitIdle(), car, comme vu dans le chapitre précédent, nous ne devons pas modifier des ressources en cours d’utilisation. Évidemment, nous allons commencer par recréer la « swap chain ». Les vues d’image doivent être recréées, car elles reposent sur les images de la « swap chain ». La passe de rendu est aussi impactée, car elle dépend du format des images de la « swap chain ». Il est rare que le format des images de la « swap chain » soit modifié lors d’un redimensionnement de la fenêtre, mais ce cas doit quand même être géré. La taille du viewport et du rectangle de découpage est spécifiée durant la création du pipeline graphique faisant que nous devons aussi reconstruire celui-ci. Sachez qu’il est possible d’éviter ce travail en utilisant les états dynamiques pour le viewport et le rectangle de découpage. Finalement, les tampons d’images et les tampons de commandes dépendent aussi directement des images de la « swap chain ».
Pour être certains que les anciens objets sont bien détruits avant d’en recréer, nous devons déplacer certains morceaux du code de nettoyage dans une nouvelle fonction. Nous nommons celle-ci cleanupSwapChain() et nous l’appelons depuis la fonction recreateSwapChain().
void cleanupSwapChain() {
}
void recreateSwapChain() {
vkDeviceWaitIdle(device);
cleanupSwapChain();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandBuffers();
}Nous allons déplacer tout le code de libération des objets qui vont être recréés avec la « swap chain », de la fonction cleanup() vers la fonction cleanupSwapChain() :
void cleanupSwapChain() {
for (size_t i = 0; i < swapChainFramebuffers.size(); i++) {
vkDestroyFramebuffer(device, swapChainFramebuffers[i], nullptr);
}
vkFreeCommandBuffers(device, commandPool, static_cast<uint32_t>(commandBuffers.size()), commandBuffers.data());
vkDestroyPipeline(device, graphicsPipeline, nullptr);
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
vkDestroyRenderPass(device, renderPass, nullptr);
for (size_t i = 0; i < swapChainImageViews.size(); i++) {
vkDestroyImageView(device, swapChainImageViews[i], nullptr);
}
vkDestroySwapchainKHR(device, swapChain, nullptr);
}
void cleanup() {
cleanupSwapChain();
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vkDestroySemaphore(device, renderFinishedSemaphores[i], nullptr);
vkDestroySemaphore(device, imageAvailableSemaphores[i], nullptr);
vkDestroyFence(device, inFlightFences[i], nullptr);
}
vkDestroyCommandPool(device, commandPool, nullptr);
vkDestroyDevice(device, nullptr);
if (enableValidationLayers) {
DestroyDebugUtilsMessengerEXT(instance, debugMessenger, nullptr);
}
vkDestroySurfaceKHR(instance, surface, nullptr);
vkDestroyInstance(instance, nullptr);
glfwDestroyWindow(window);
glfwTerminate();
}Ce serait du gâchis de recréer le groupe de commandes à partir de zéro. J'ai préféré libérer les tampons de commandes existants à l'aide de la fonction vkFreeCommandBuffers(). De cette manière, nous pouvons réutiliser le groupe de commandes pour allouer de nouveaux tampons de commandes.
Pour gérer correctement le redimensionnement de la fenêtre, nous devons aussi récupérer la taille actuelle du tampon d’images afin de nous assurer que les images de la « swap chain » ont bien la nouvelle taille. Pour cela, modifiez la fonction chooseSwapExtent() afin que cette fonction prenne en compte la taille actuelle :
VkExtent2D chooseSwapExtent(const VkSurfaceCapabilitiesKHR& capabilities) {
if (capabilities.currentExtent.width != UINT32_MAX) {
return capabilities.currentExtent;
} else {
int width, height;
glfwGetFramebufferSize(window, &width, &height);
VkExtent2D actualExtent = {
static_cast<uint32_t>(width),
static_cast<uint32_t>(height)
};
...
}
}C'est tout ce que nous avons à faire pour recréer la « swap chain » ! Cependant, le problème de cette approche est que nous devons arrêter le rendu avant de créer la nouvelle « swap chain ». Il est possible de créer une nouvelle « swap chain » tout en continuant l’exécution de commandes de rendu sur une image provenant de l’ancienne « swap chain ». Pour cela, vous devez passer l'ancienne « swap chain » en paramètre dans le champ oldSwapChain de la structure VkSwapchainCreateInfoKHR et détruire cette ancienne « swap chain » dès que vous ne l'utilisez plus.
IV-E-3. Swap chain non optimale ou obsolète▲
Nous devons maintenant déterminer quand recréer la « swap chain » et donc quand appeler la fonction recreateSwapChain(). Heureusement, Vulkan nous indiquera que la « swap chain » n'est plus appropriée au moment de la présentation. Les fonctions vkAcquireNextImageKHR() et vkQueuePresentKHR() peuvent, dans ce cas, retourner les valeurs suivantes :
- VK_ERROR_OUT_OF_DATE_KHR : la « swap chain » n'est plus compatible avec la surface et ne peut plus être utilisée pour le rendu. Cela se produit après un redimensionnement de la fenêtre ;
- VK_SUBOPTIMAL_KHR : la « swap chain » peut toujours être utilisée pour présenter des images à la surface, mais les propriétés de la surface ne correspondent plus exactement.
VkResult result = vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);
if (result == VK_ERROR_OUT_OF_DATE_KHR) {
recreateSwapChain();
return;
} else if (result != VK_SUCCESS && result != VK_SUBOPTIMAL_KHR) {
throw std::runtime_error("Échec lors de la récupération de l’image de la « swap chain » !");
}Si la « swap chain » se retrouve obsolète lorsque nous essayons d’obtenir une nouvelle image, il devient aussi impossible d’en afficher. Nous devons alors immédiatement recréer une « swap chain » et réessayer au prochain appel à la fonction drawFrame().
Vous pouvez aussi décider de recréer la « swap chain » si elle n'est plus optimale, mais j'ai décidé de continuer l’affichage, car nous avons déjà obtenu une image. Ainsi, les deux cas VK_SUCCES et VK_SUBOPTIMAL_KHR sont considérés comme des valeurs indiquant un succès.
result = vkQueuePresentKHR(presentQueue, &presentInfo);
if (result == VK_ERROR_OUT_OF_DATE_KHR || result == VK_SUBOPTIMAL_KHR) {
recreateSwapChain();
} else if (result != VK_SUCCESS) {
throw std::runtime_error("Impossible de présenter une image de la swap chain !");
}
currentFrame = (currentFrame + 1) % MAX_FRAMES_IN_FLIGHT;La fonction vkQueuePresentKHR() utilise les mêmes valeurs pour les mêmes raisons. Dans ce cas, nous recréons la « swap chain » aussi dans le cas où elle n'est plus optimale, car nous souhaitons les meilleurs résultats possible.
IV-E-4. Gestion explicite des redimensionnements▲
Bien que la plupart des pilotes envoient automatiquement le code VK_ERROR_OUT_OF_DATE_KHR après qu'une fenêtre a été redimensionnée, cela n'est en aucun cas garanti. C’est pourquoi nous allons ajouter un code supplémentaire pour gérer explicitement les redimensionnements. Premièrement, ajoutez une nouvelle variable membre qui indique qu’un redimensionnement a eu lieu :
std::vector<VkFence> inFlightFences;
size_t currentFrame = 0;
bool framebufferResized = false;Modifiez ensuite la fonction drawFrame() pour prendre en compte cette nouvelle variable :
if (result == VK_ERROR_OUT_OF_DATE_KHR || result == VK_SUBOPTIMAL_KHR || framebufferResized) {
framebufferResized = false;
recreateSwapChain();
} else if (result != VK_SUCCESS) {
...
}Il est important de faire cela après la fonction vkQueuePresentKHR() pour s’assurer que les sémaphores sont dans un état consistant. Autrement, un sémaphore déclenché ne pourra plus jamais être utilisé pour effectuer une attente. Afin de détecter les redimensionnements, nous pouvons utiliser la fonction glfwSetFrameBufferSizeCallback() fournie par le framework GLFW pour mettre en place une fonction callback :
void initWindow() {
glfwInit();
glfwWindowHint(GLFW_CLIENT_API, GLFW_NO_API);
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);
glfwSetFramebufferSizeCallback(window, framebufferResizeCallback);
}
static void framebufferResizeCallback(GLFWwindow* window, int width, int height) {
}Nous devons utiliser une fonction statique comme callback, car GLFW ne sait pas correctement appeler une fonction membre d'une classe avec le bon pointeur this pointant sur notre instance de la classe HelloTriangleApplication.
Toutefois, nous obtenons une référence du type GLFWwindow dans la fonction callback que nous fournissons. De plus, nous pouvons stocker le pointeur de notre choix dans une instance GLFW grâce à la fonction glfwSetWindowUserPointer() :
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);
glfwSetWindowUserPointer(window, this);
glfwSetFramebufferSizeCallback(window, framebufferResizeCallback);La valeur stockée peut être récupérée dans la fonction callback grâce à la fonction glfwGetWindowUserPointer() afin de changer la valeur de notre variable indiquant un redimensionnement :
static void framebufferResizeCallback(GLFWwindow* window, int width, int height) {
auto app = reinterpret_cast<HelloTriangleApplication*>(glfwGetWindowUserPointer(window));
app->framebufferResized = true;
}Lancez maintenant le programme et redimensionnez la fenêtre pour voir si le tampon d’image est correctement redimensionné avec la fenêtre.
IV-E-5. Gestion de la minimisation de la fenêtre▲
Il existe un autre cas important où la « swap chain » peut devenir obsolète : si la fenêtre est minimisée. Ce cas est particulier, car la taille du tampon d’image devient nulle. Dans ce tutoriel, nous allons gérer cela en mettant en pause la fenêtre jusqu’à ce que la fenêtre soit à nouveau remise au premier plan. Nous modifions la fonction recreateSwapChain() pour ce nouveau cas :
void recreateSwapChain() {
int width = 0, height = 0;
glfwGetFramebufferSize(window, &width, &height);
while (width == 0 || height == 0) {
glfwGetFramebufferSize(window, &width, &height);
glfwWaitEvents();
}
vkDeviceWaitIdle(device);
...
}L'appel initial à la fonction glfwGetFramebufferSize() prend en charge le cas où la taille est déjà correcte et glfwWaitEvents() n'aurait rien à attendre.
Félicitations, vous avez créé votre premier programme fonctionnel avec Vulkan ! Dans le prochain chapitre, nous allons supprimer les sommets en dur du vertex shader et mettre en place un tampon de sommets.
